-
paper link: 13-llama3.pdf
-
website link: https://ai.meta.com/blog/meta-llama-3/
-
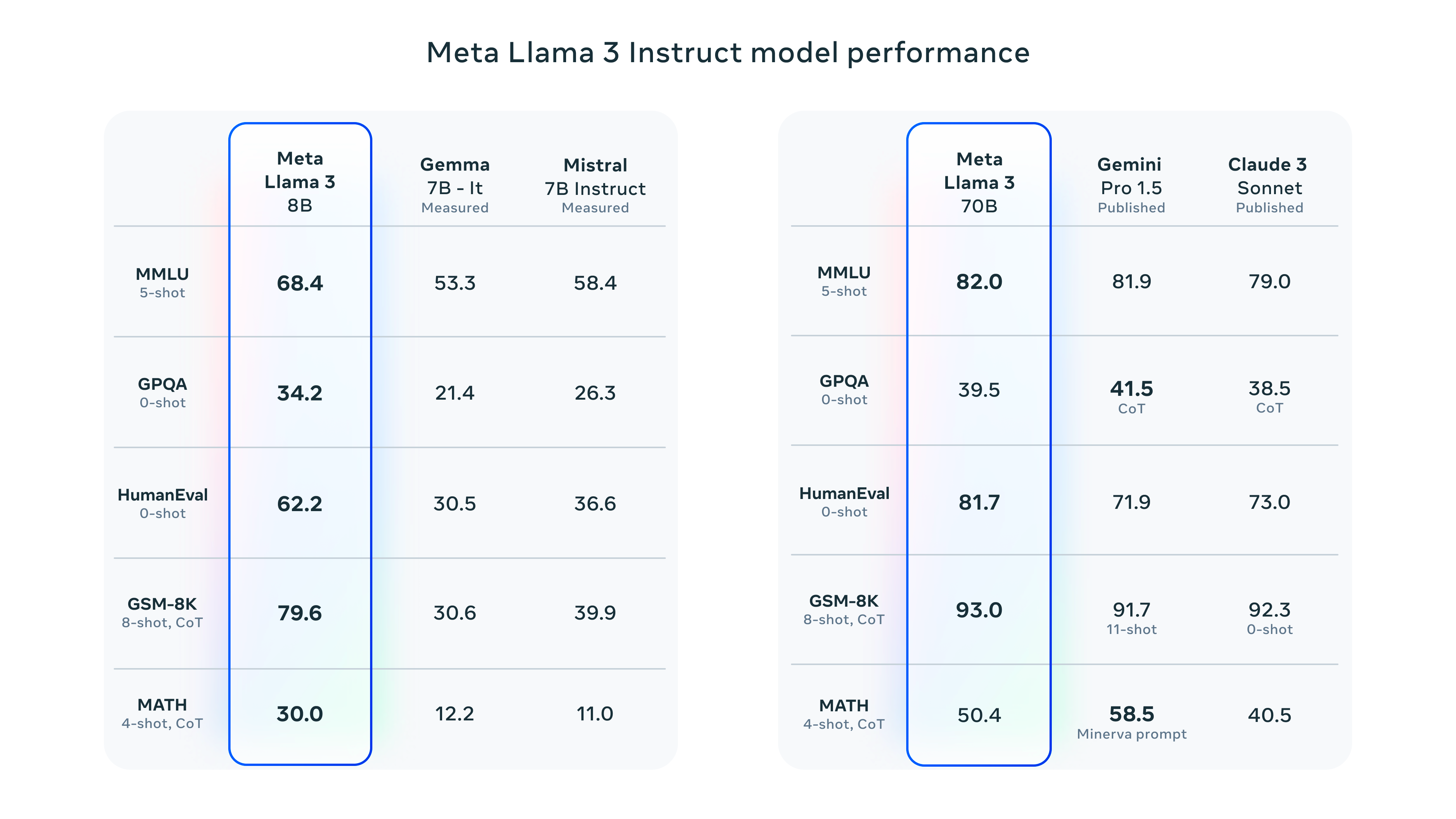
Evaluation results
Architectural details
- decoder-only transformer
- Llama 3 uses a tokenizer with a vocabulary of 128K tokens
- To improve the inference efficiency of Llama 3 models, we’ve adopted grouped query attention (GQA) across both the 8B and 70B sizes.
- We trained the models on sequences of 8,192 tokens, using a mask to ensure self-attention does not cross document boundaries.
Training data
- pretrained on over 15T tokens that were all collected from publicly available sources. Our training dataset is seven times larger than that used for Llama 2, and it includes four times more code.
- To prepare for upcoming multilingual use cases, over 5% of the Llama 3 pretraining dataset consists of high-quality non-English data that covers over 30 languages.
- To ensure Llama 3 is trained on data of the highest quality, we developed a series of data-filtering pipelines. These pipelines include using heuristic filters, NSFW filters, semantic deduplication approaches, and text classifiers to predict data quality. We found that previous generations of Llama are surprisingly good at identifying high-quality data, hence we used Llama 2 to generate the training data for the text-quality classifiers that are powering Llama 3.
- these improvements increased the efficiency of Llama 3 training by ~three times compared to Llama 2.
Instruction fine-tuning
- Our approach to post-training is a combination of
- supervised fine-tuning (SFT)
- rejection sampling
- proximal policy optimization (PPO)
- direct preference optimization (DPO).
- We found that if you ask a model a reasoning question that it struggles to answer, the model will sometimes produce the right reasoning trace: The model knows how to produce the right answer, but it does not know how to select it. Training on preference rankings enables the model to learn how to select it.
General Overview
- Aşağıdakilere ek olarak image, video, and speech için ayrı modeller de train edip llama3 e entegre etmişler
- Language model pre-training: Pretrain an LLM to perform next-token prediction
- Language model post-training:
-
SFT on instruction tuning data
-
DPO
-

1. Pretraining
- Web Data Curation → 13-llama3, page 4
- Determining Data Mix → 13-llama3, page 6
- Annealing Data → 13-llama3, page 6
- ”Empirically, we find that annealing (see Section 3.4.3) on small amounts of high-quality code and mathematical data can boost the performance of pre-trained models on key benchmarks”
- Data annealing involves gradually adjusting the data or training process to improve model performance, stability, and efficiency.
1.1. Model Architecture
- It does not deviate significantly from Llama and Llama 2 in terms of model architecture
- Changes:
- We use grouped query attention (GQA; Ainslie et al. (2023)) with 8 key-value heads to improve inference speed and to reduce the size of key-value caches during decoding.
- We use an attention mask that prevents self-attention between different documents within the same sequence. We find that this change had limited impact during in standard pre-training, but find it to be important in continued pre-training on very long sequences.
- We use a vocabulary with 128K tokens. Our token vocabulary combines 100K tokens from the tiktoken3 tokenizer with 28K additional tokens to better support non-English languages. Compared to the Llama2 tokenizer, our new tokenizer improves compression rates on a sample of English data from 3.17 to 3.94 characters per token. This enables the model to “read” more text for the same amount of training compute. We also found that adding 28K tokens from select non-English languages improved both compression ratios and downstream performance, with no impact on English tokenization.
- We increase the RoPE base frequency hyperparameter to 500,000. This enables us to better support longer contexts; Xiong et al. (2023) showed this value to be effective for context lengths up to 32,768.
1.2. Training Recipe
1.2.1. Initial pre-training
1.2.2. Long-context pre-training
- ”In the final stages of pre-training, we train on long sequences to support context windows of up to 128K tokens. We do not train on long sequences earlier because the compute in self-attention layers grows quadratically in the sequence length.”
1.2.3. Annealing
- ”During pre-training on the final 40M tokens, we linearly annealed the learning rate to 0, maintaining a context length of 128K tokens.”
2. Post-training
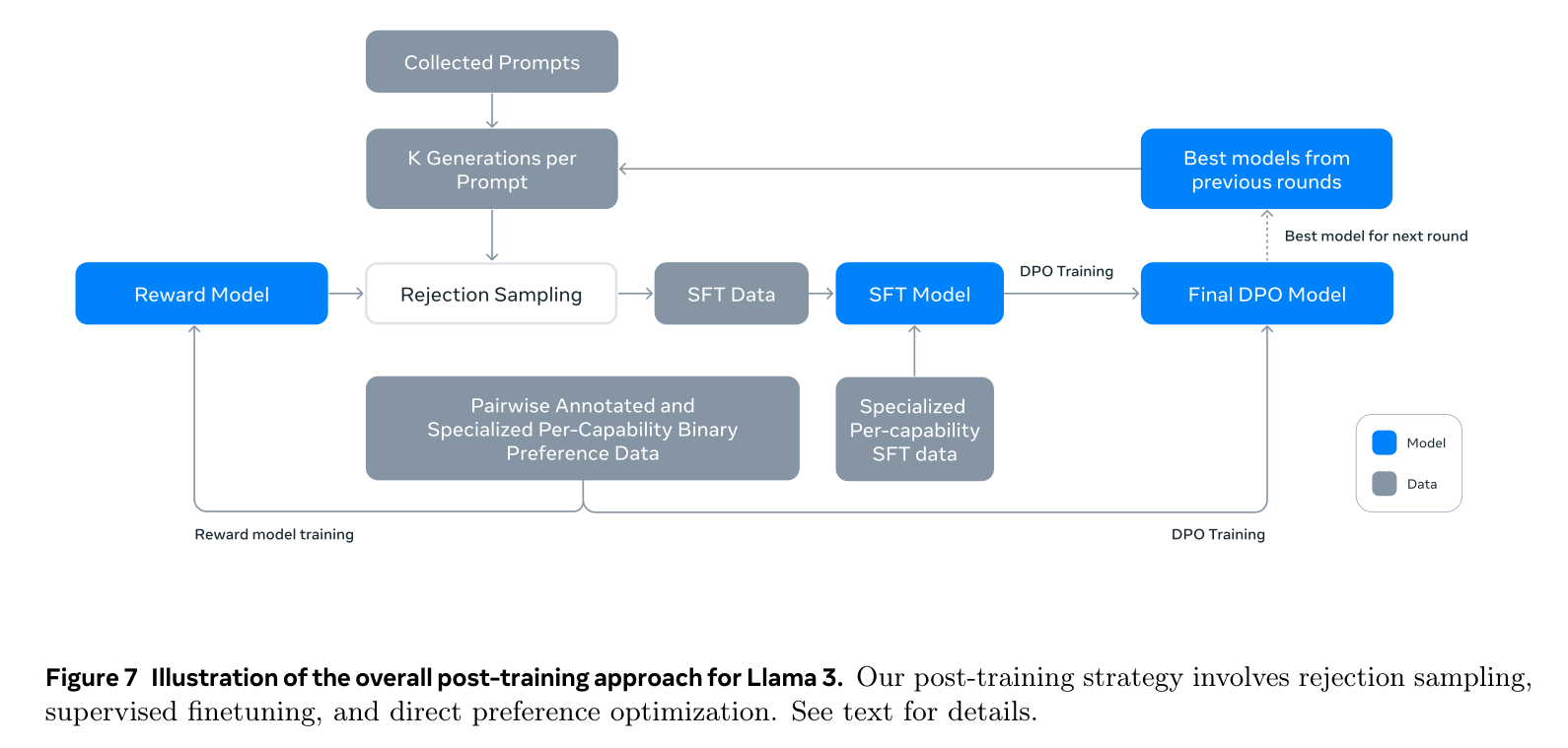
2.1. Modeling
- We first train a reward model on top of the pre-trained checkpoint using human-annotated preference data (see Section 4.1.2).
- We then finetune pre-trained checkpoints with supervised finetuning (SFT; see Section 4.1.3), and further align the checkpoints with Direct Preference Optimization (DPO; see Section 4.1.4).
2.1.1. Reward Modeling (RM)
- The training objective is the same as Llama 2 except that we remove the margin term in the loss, as we observe diminishing improvements after data scaling.
- Following Llama 2, we use all of our preference data for reward modeling after filtering out samples with similar responses.
- In addition to standard preference pair of (chosen, rejected) response, annotations also create a third “edited response” for some prompts, where the chosen response from the pair is further edited for improvement (see Section 4.2.1). Hence, each preference ranking sample has two or three responses with clear ranking (edited > chosen > rejected ).
2.1.2. SFT
- The reward model is then used to perform rejection sampling on our human annotation prompts.
- Together with this rejection-sampled data and other data sources (including synthetic data), we finetune the pre-trained language model using a standard cross entropy loss on the target tokens (while masking loss on prompt tokens).
2.1.3. DPO
- For training, we primarily use the most recent batches of preference data collected using the best performing models from the previous alignment rounds. As a result, our training data conforms better to the distribution of the policy model that is being optimized in each round.
2.1.4. Model Averaging
- Finally, we average models obtained from experiments using various versions of data or hyperparameters at each RM, SFT, or DPO stage
Capabilities
- Code
- Synthetic data generation: execution feedback
- Problem description generation
- Solution generation
- Correctness analysis
- Error feedback and iterative self-correction
- Fine-tuning and iterative improvement
- Synthetic data generation: programming language translation
- Synthetic data generation: backtranslation
- Synthetic data generation: execution feedback
- Multilinguality
- ”Our multilingual SFT data is derived primarily from sources described below. The overall distribution is 2.4% human annotations, 44.2% data from other NLP tasks, 18.8% rejection sampled data, and 34.6% translated reasoning data.”
- Math and Reasoning
- Long Context
- QA
- Summarization
- Long context code reasoning
- Tool Use
- Search engine. Llama 3 is trained to use Brave Search7 to answer questions about recent events that go beyond its knowledge cutoff or that require retrieving a particular piece of information from the web.
- Python interpreter. Llama 3 can generate and execute code to perform complex computations, read files uploaded by the user and solve tasks based on them such as question answering, summarization, data analysis or visualization.
- Mathematical computational engine. Llama 3 can use the Wolfram Alpha API8 to more accurately solve math, science problems, or retrieve accurate information from Wolfram’s database.
- The resulting model is able to use these tools in a chat setup to solve the user’s queries, including in multi-turn dialogs. If a query requires multiple tool calls, the model can write a step-by-step plan, call the tools in sequence, and do reasoning after each tool call.
Results
- model performansı sonuçları için paperın 13-llama3, page 28 sayfasına bakılabilir.
- speech, image, video to text modelleri için gerekirse paper further incelenbilri.