- Output.json dosyasında 110 query var. Query ler birbirleri ile aynı da olabiliyor.
- Retrieved chunk’ı relevant olan 25 tane (query, retrieved_chunk) pair var.
- Retrieved chunk’ı partially relevant olan 51 (query, retrieved_chunk) pair var.
Oquzhansahin modeli
- Genel similarity ler çok düşük çıkıyor 0.3 civarlarında
- Relevant answer in first answer: 14
- Partial answers in top-5: 5
- Relevant answers in top-5: 24
Oguzhansahin-finetune
- Similarity scorelar daha yüksek 0.4 civarlarında
- Relevant answer in first answer: 10
- Partial answers in top-5: 8
- Relevant answers in top-5: 18
Emrecan
- Relevant answer in first answer: 10
- Partial answers in top-5: 6
- Relevant answers in top-5: 19
Atasoglu
- Relevant answer in first answer: 8
- Partial answers in top-5: 5
- Relevant answers in top-5: 16
Multilingual - jhgan/ko-sroberta-multitask
- Döndüğü top-5’ın relevance scorelar çok çok daha yüksek 0.7 lerde
- Relevant answer in the first answer: 6
- Partial answers in top-5: 2
- Relevant answers in top-5: 11
Multilingual - Alibaba-NLP/gte-multilingual-base
- Döndüğü top-5’ın relevance scorelar çok çok daha yüksek 0.6 larde
- Relevant answer in first answer: 13
- Partial answers in top-5: 9
- Relevant answers in top-5: 23
- Histogram results:
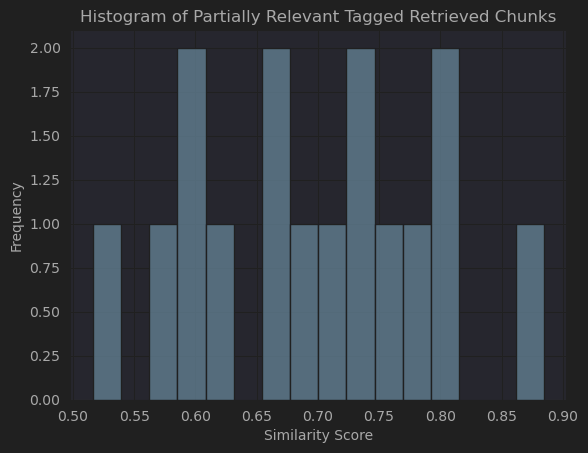
- There are 16 reviews with “Partially Relevant”
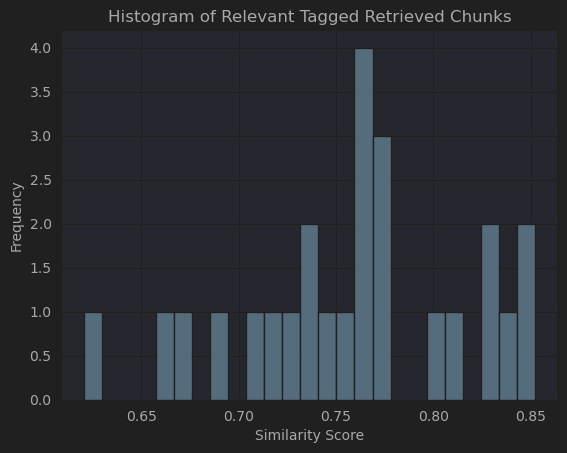
- There are 25 reviews with “Relevant”
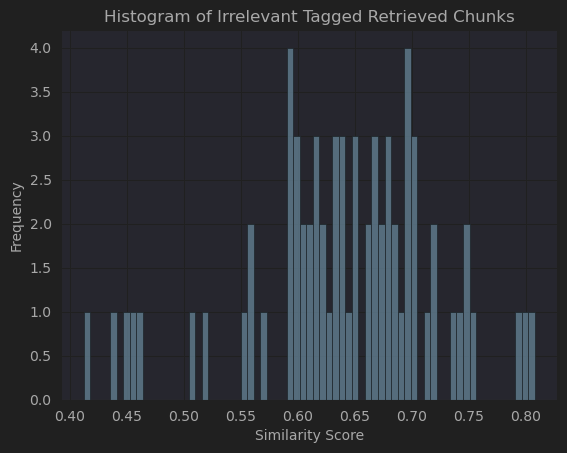
- There are 69 reviews with “Irrelevant”
- There are 16 reviews with “Partially Relevant”
Finetuned Alibaba NLP
- Relevant answer in first answer: 3
- Partial answers in top-5: 4
- Relevant answers in top-5: 8
TODO
- Finetuned model üzerinde inference al
- İrrelevant, partially relevant, relevant scorelarına göre histogram yap
- multilingual model bul ve inference al
- multilingual mıdeli fine tune et
- irrelvanta verilen score lar, relevant scoreları, partially relevant socreları histogram yap
- finetune yaptığım modelde dene,
- finetune sonrası oğuzhan sahin ile compare et
- multilinugal bul, onun üzerinde de dene
- query chunk class larına göre histogram yap score larına göre
- sentetk dataseti oluşturma, wikipedia dataseti üzerine, chunkları da kaydediblirsin
- query ve contexting geçtiği transformers modeli farklı olabilir
- acaba sentence similarity bulmak için query ve contextleri translate edip bir model mi kullansak sonra zaten türkçeiçin train edilmiş verileri direkt veririz llm e