https://osanseviero.github.io/hackerllama/blog/posts/sentence_embeddings2/
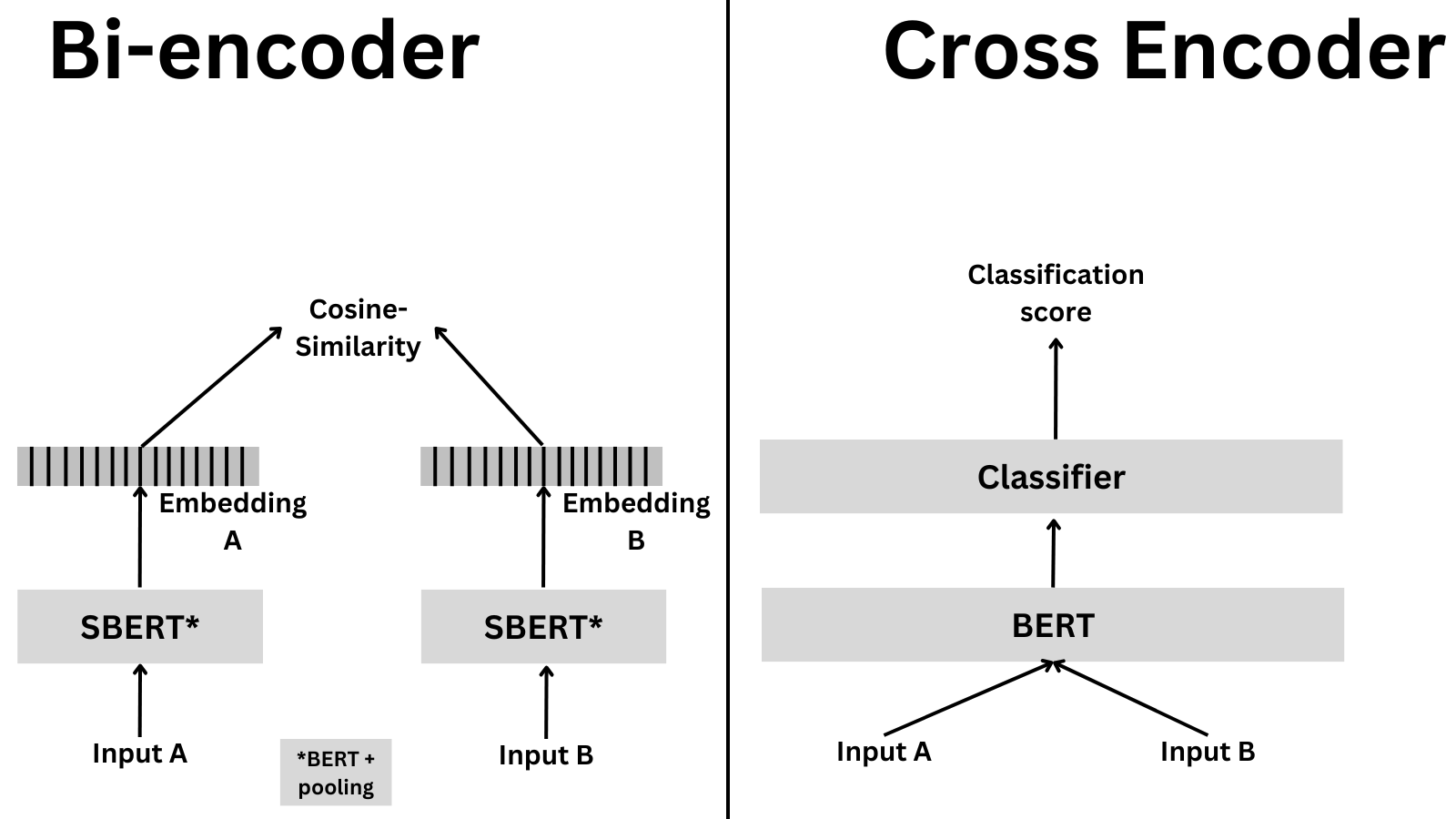
- We train bi-encoders to optimize the increase in the similarity between the query and relevant sentences and decrease the similarity between the query and the other sentences.
- If multiple sentences are provided, the bi-encoder will encode each sentence independently.
- Bi-encoder doesn’t know anything about the relationship between the sentences.
- Cross-encoders encode the two sentences simultaneously and then output a classification score.
- Cross-encoders are slower and more memory intensive but also much more accurate.
- The cross-encoder first generates a single embedding that captures representations and their relationships. It produces then an output value between 0 and 1 indicating the similarity of the input sentence pair.
- As detailed in BERT paper, Cross-Encoder achieve better performances than Bi-Encoders.