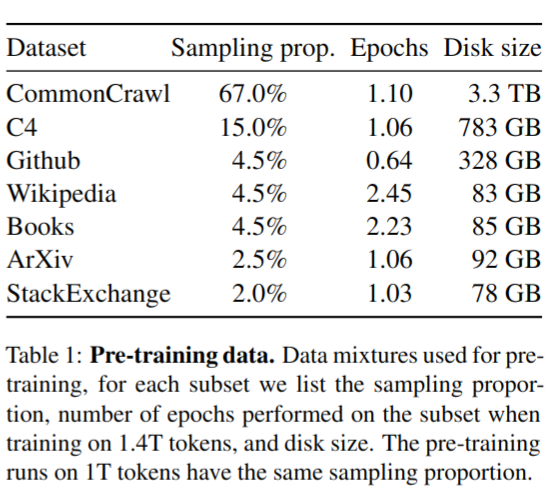
Llama 1 is trained on a publicly available text data.
”Recent work from Hoffmann et al. (2022) shows that, for a given compute budget, the best performances are not achieved by the largest models, but by smaller models trained on more data.” → ulaşmaya çalıştıkları bu
Tokenizer: We tokenize the data with the byte-pair encoding (BPE) algorithm (Sennrich et al., 2015), using the implementation from Sentence-Piece (Kudo and Richardson, 2018). Notably, we split all numbers into individual digits, and fallback to bytes to decompose unknown UTF-8 characters.
Architectural Decisions:
Pre-normalization [GPT3]. Normalde her her bir encoder decoder layer için sublayer ların son aşamasında output normalization yapılıyor. Bunun yerine her bir sub-layerın inputunu normalize etmişlerasked→ Ben burayı anlamadım yani ilk sublayer inputunu da normalize etmek dışında bir farklılık yapılmamış aslında??
SwiGLU activation function [PaLM]. Instead of ReLU, SwiGLU activation function is used to improve performance
Rotary Embeddings [GPTNeo]. We remove the absolute positional embeddings, and instead, add rotary positional embeddings (RoPE)
Optimizer: AdamW
Multihead attention kullanmışlar
Efficiency artırmak için decoderda kullanılan masked self attention mekanizmasında 0 olan weightleri storelamamışlar
To further improve training efficiency, we reduced the amount of activations that are recomputed during the backward pass with checkpoint. More precisely, we save the activations that are expensive to compute, such as the outputs of linear layers. This is achieved by manually implementing the backward function for the transformer layers, instead of relying on the PyTorch autograding. ask
Pre-train yaptıktan sonra zero-shot ve few-shot learning ile çeşitli tasklar üzerinde llama skorlarını paylaşmışlar