Potential Read Path
- 1-instruction-following.pdf
- 2-llama1.pdf
- 3-llama2.pdf
- 4-lms_are_few_shot_learners.pdf + https://www.youtube.com/watch?v=SY5PvZrJhLE&t=1888s&ab_channel=YannicKilcher (first 30 minutes)
- 5-lms_are_unsupervised_multitask_learners.pdf
- 6-llama3
- https://jalammar.github.io/visualizing-neural-machine-translation-mechanics-of-seq2seq-models-with-attention/
- A friendly introduction to Recurrent Neural Networks: https://www.youtube.com/watch?v=UNmqTiOnRfg
- https://jalammar.github.io/illustrated-transformer/
- jury paper
- BERT paper
- GQA: https://medium.com/@raisomya360/demystifying-sliding-window-grouped-query-attention-a-simpler-approach-to-efficient-neural-6fb03b7d021f
- 7-SentencePiece.pdf
- Byte-pair encoding: https://www.geeksforgeeks.org/byte-pair-encoding-bpe-in-nlp/
Key points
Instruction following
LLMs are few shot learners
Jalammar Attention Blogpost
Jalammar Transformers Blogpost
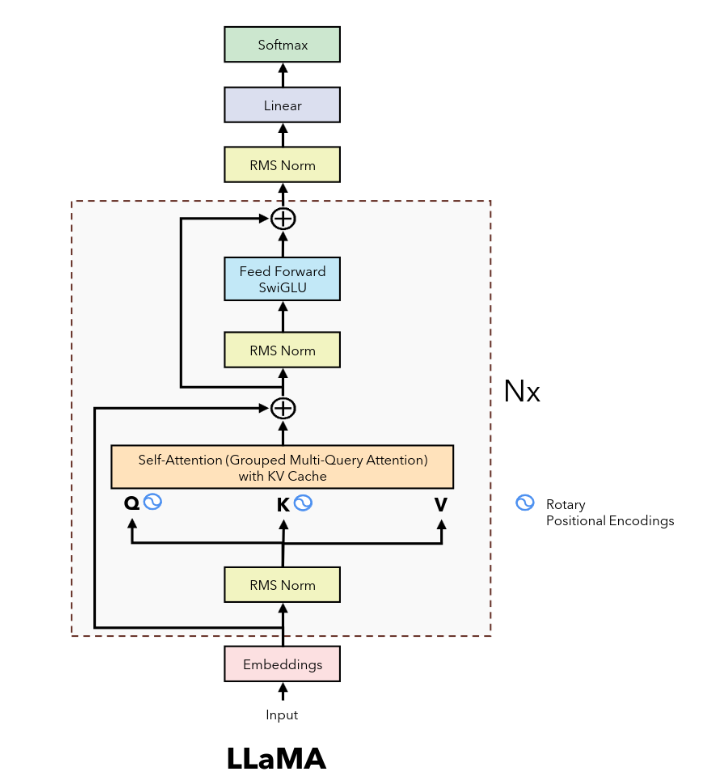
Llama family
Llama-1
Llama-2