-
paper link: 12-textual-sim-paper.pdf
-
This study aims to develop a general text embedding model through a multi-stage training approach.
-
In the initial stage of unsupervised contrastive learning, we generate weak supervised correlation text pairs using publicly available data from various sources.
-
In the supervised fine-tuning stage, the mixture of training data in our approach is more varied to further enhance the model’s versatility.
-
The training process of our model consists of two stages: unsupervised pre-training and supervised fine-tuning. Both stages employ the learning objective of contrastive learning.
Model Architecture
- The backbone of our embedding model is a deep Transformer encoder which can be initialized with pre-trained language models such as BERT (Devlin et al., 2019).
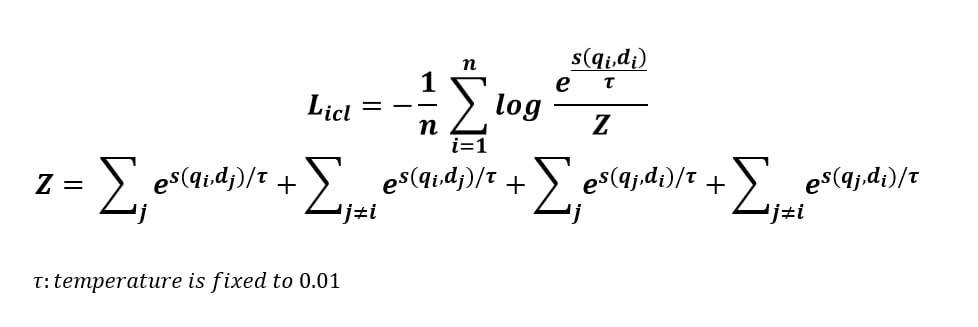
Unsupervised Pre-training Data
- Weakly supervised text relevance data is readily available in publicly accessible web sources, such as the inherent connection between queries and answers on QA forums.
- Model is initially pre-trained on naturally occurring text pairs extracted from diverse sources.
Supervised Fine-tuning Data
- In the supervised fine-tuning stage, we use relatively lower-sized datasets with human annotation of the relevance between two pieces of text and optional hard negatives mined by an extra retriever to form text triples.
Training Details
- imbalanced data → they employ a multinomial distribution to sample data batches from different data sources, taking into account their respective sizes.
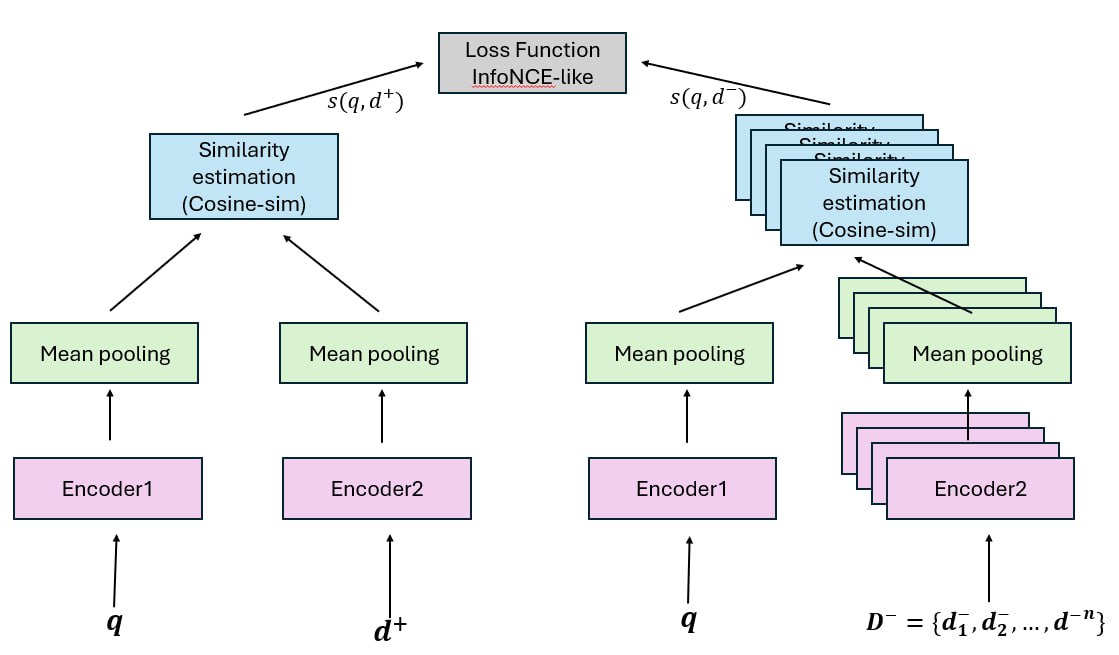
- They use improved contrastive loss
- ICL is bidirectional and enlarges the negative samples with both in-batched queries and documents.
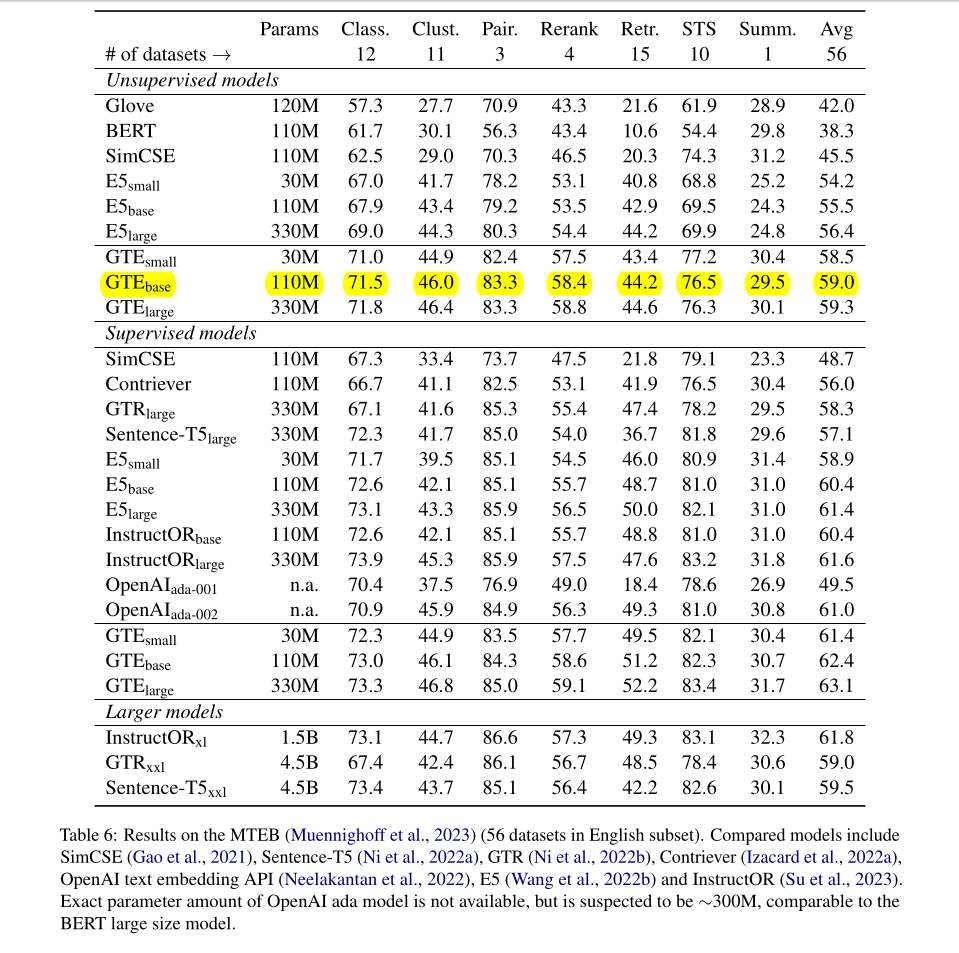
Results