-
paper link : 14-bert.pdf
-
blogpost link: https://medium.com/towards-data-science/bert-3d1bf880386a
-
Bert is a language representation model
-
BERT stands for Bidirectional Encoder Representations from Transformers
-
BERT uses a cross-encoder. It supplies a pair of sentences as an input.
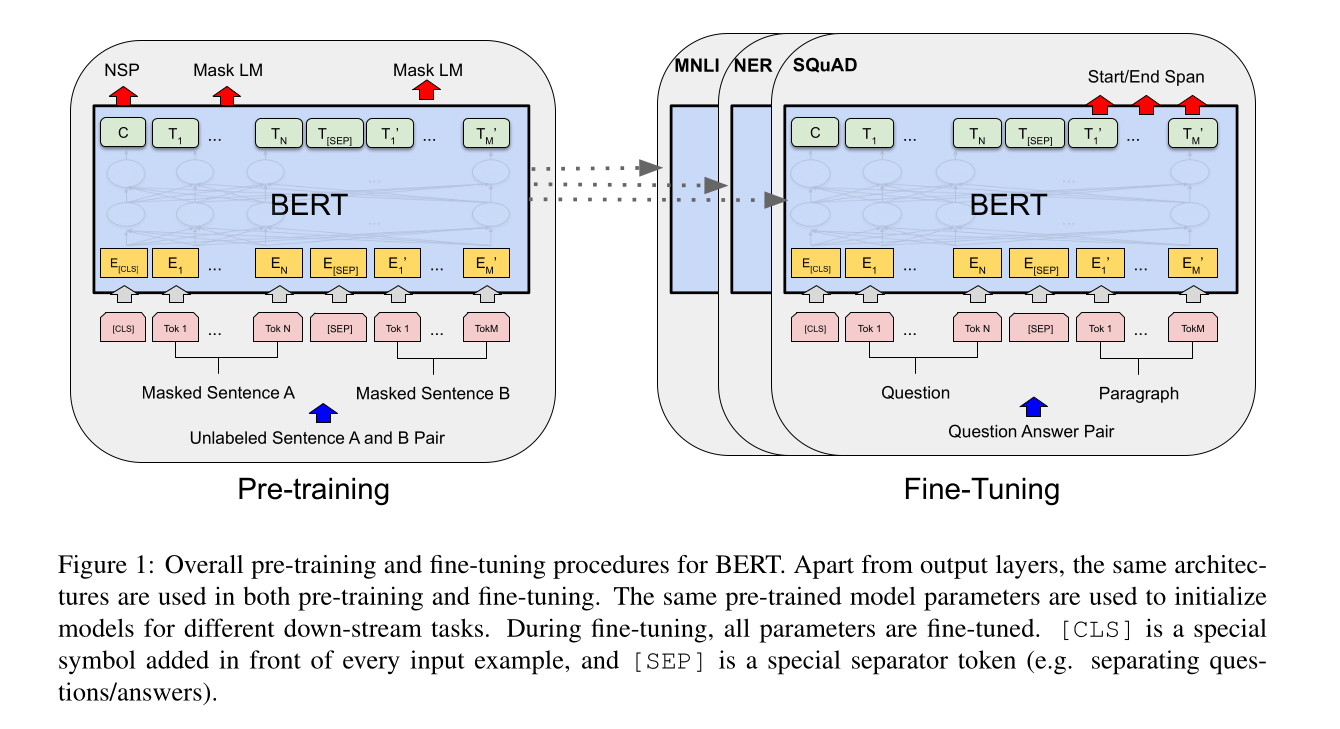
The differences between Bert-base and Bert-large
Unidirectional vs. Bidirectional Models
Pretraining BERT
The whole picture
Which embeddings do they use for tokenization?
- In BERT, WordPiece embeddings is used.
- Here is a proper explanation for WordPiece embeddings: https://huggingface.co/learn/nlp-course/en/chapter6/6
Input
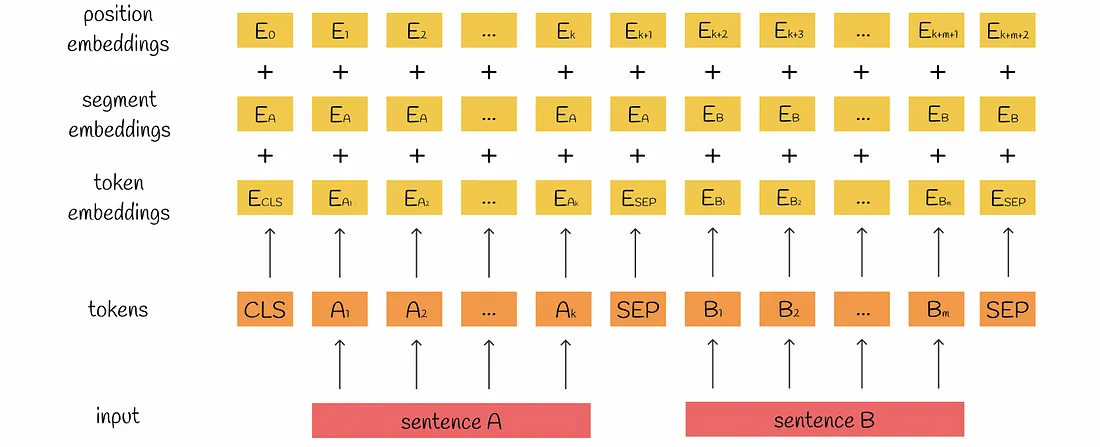 These embeddings are summed up and the result is passed to the first encoder of the BERT model.
These embeddings are summed up and the result is passed to the first encoder of the BERT model.
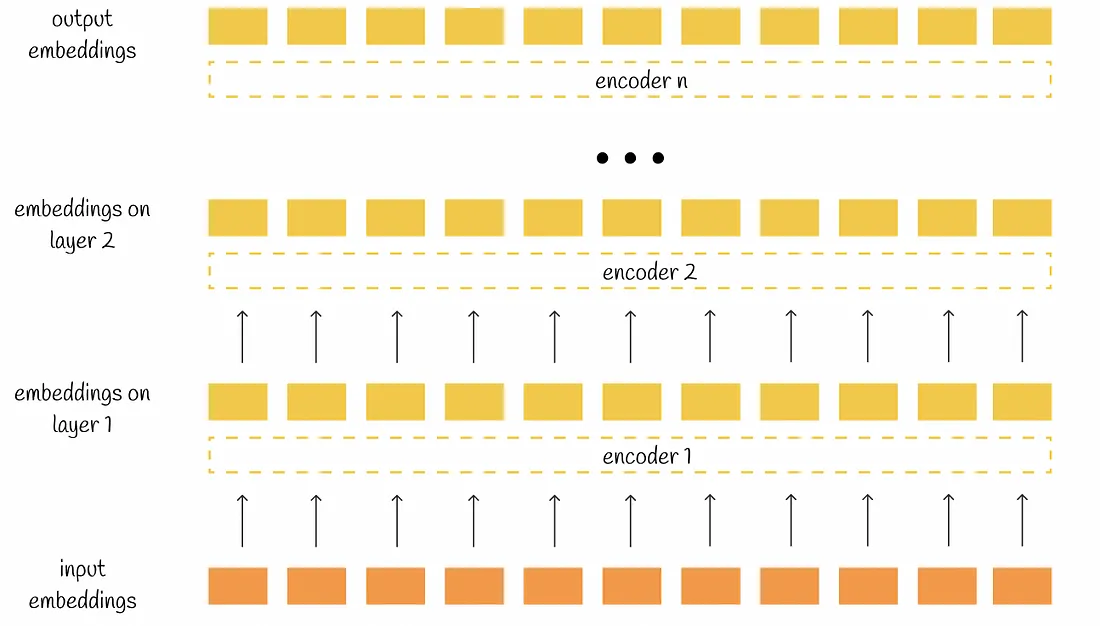
Output
Each encoder takes n embeddings as input and then outputs the same number of processed embeddings of the same dimensionality. Ultimately, the whole BERT output also contains n embeddings each of which corresponds to its initial token.
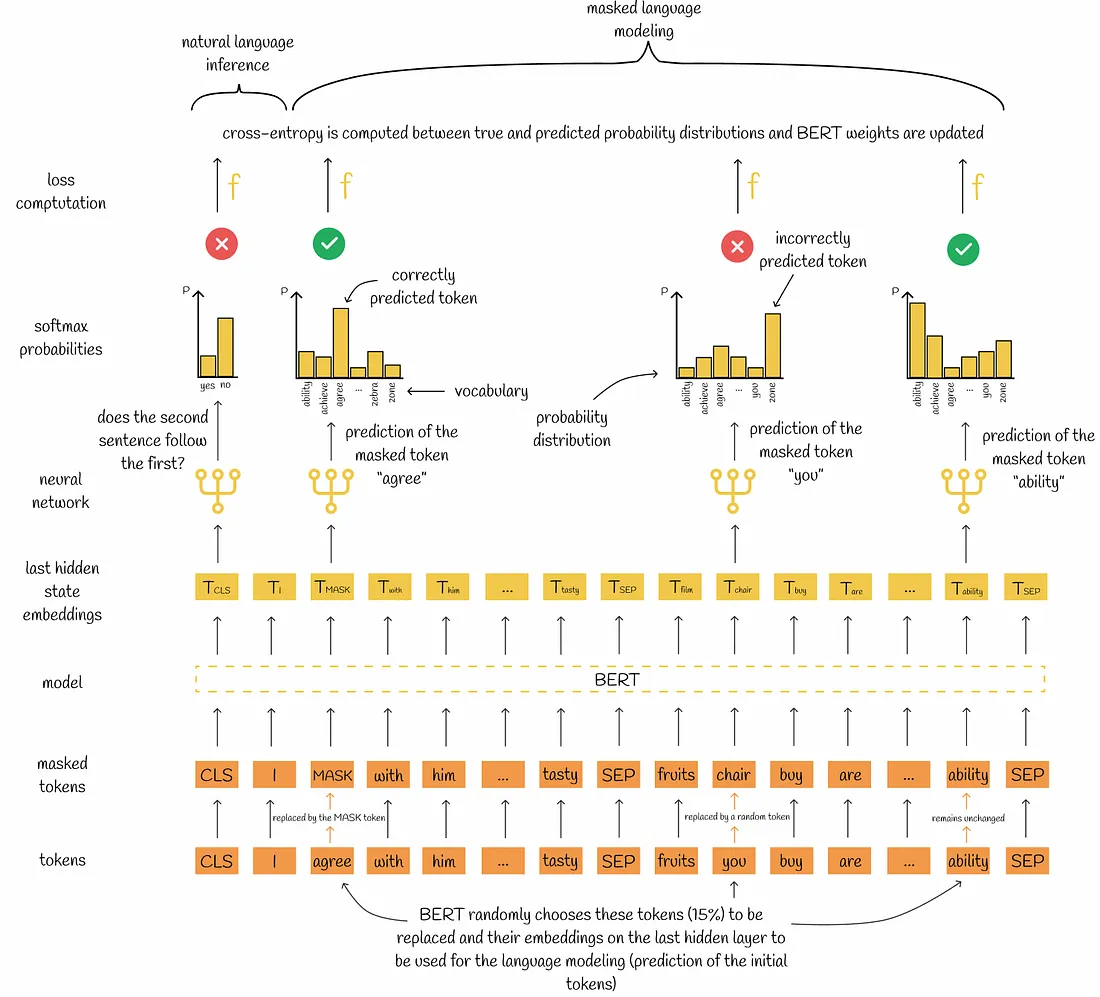
Example 1: Masked Language Modeling (MLM)
In MLM, some tokens in the input sentences are randomly masked, and the model is trained to predict these masked tokens. This process creates a supervised learning problem within the unsupervised data.
- Input: “The quick brown [MASK] jumps over the lazy dog.”
- Objective: Predict the masked token “fox”.
The model learns to predict the masked tokens based on the context provided by the other tokens in the sentence. This helps the model understand language structure and word relationships.
Example 2: Next Sentence Prediction (NSP)
In NSP, the model is trained to predict whether a given sentence is the immediate next sentence of another. This involves pairs of sentences.
- Positive Pair: (“The quick brown fox jumps over the lazy dog.”, “It was a sunny day.“)
- Negative Pair: (“The quick brown fox jumps over the lazy dog.”, “The stock market crashed yesterday.“)
The model learns to predict if the second sentence logically follows the first one, helping it understand sentence relationships and coherence.
Training Parameters
According to the original paper, the training parameters are the following:
- Optimizer: Adam (learning rate l = 1e-4, weight decay L₂ = 0.01, β₁ = 0.9, β₂ = 0.999, ε = 1e-6).
- Learning rate warmup is performed over the first 10 000 steps and then reduced linearly.
- Dropout (α = 0.1) layer is used on all layers.
- Activation function: GELU.
- Training loss is the sum of mean MLM and mean next sentence prediction likelihoods.
TASK1: MLM
- Mask some percentage of the input token at random
- Predict those masked tokens
- Final hidden vectors corresponding to the mask tokens are fed into an output softmax
- Only predict the masked words Denoising Autoencoder vs. Masked LMs
Masked LM and the Masking Procedure: Assuming the unlabeled sentence is my dog is hairy, and during the random masking procedure we chose the 4-th token (which corresponding to hairy), our masking procedure can be further illustrated by
• 80% of the time: Replace the word with the [MASK] token, e.g., my dog is hairy → my dog is [MASK] • 10% of the time: Replace the word with a random word, e.g., my dog is hairy → my dog is apple • 10% of the time: Keep the word unchanged, e.g., my dog is hairy → my dog is hairy.
The cross-entropy loss is calculated by comparing probability distributions with the true masked tokens.
ask her sentence yalnız kendisinden önceki sentenci kullanarak bir context mi okuyor yoksa kendisinden önceki sentence’ın cls tokeni ondan da önceki sentence hakkında bilgi taşıyor mu
How to eliminate mismatch between pretraining and fine-tuning?
- pretrain sırasında MLM yapıyoruz yani her inputtan en az 1 kelime [MASK] tokenini içeriyor. Ama fine-tuningde böyle bir şey söz konusu değil.
- Solution:
- Choose 15% of the token positions at random
- Replace each chosen token with [MASK] with 80% probability
- Replace each chosen token with a random token with 10% of the time
- Unchange each chosen token with 10% of the time
TASK2: NSP
-
”Specifically, when choosing the sentences A and B for each pre- training example, 50% of the time B is the actual next sentence that follows A (labeled as IsNext), and 50% of the time it is a random sentence from the corpus (labeled as NotNext).”
-
Next Sentence Prediction The next sentence prediction task can be illustrated in the following examples. Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP] Label = IsNext
Input = [CLS] the man [MASK] to the store [SEP] penguin [MASK] are flightless birds [SEP] Label = NotNext