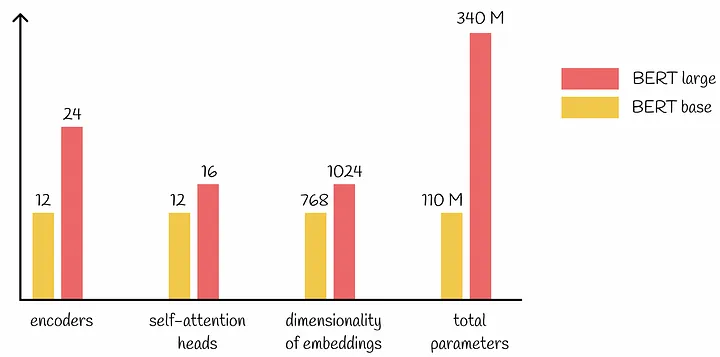
Model size differs: L : number of layers (transformer blocks) H : hidden size A : number self-attention heads base → L = 12, H = 768, A = 12, total-params: 110M large → L = 24, H = 1024, A = 16, total-params: 340M