Coursera Deep Learning Spec Course Module 1.pdf










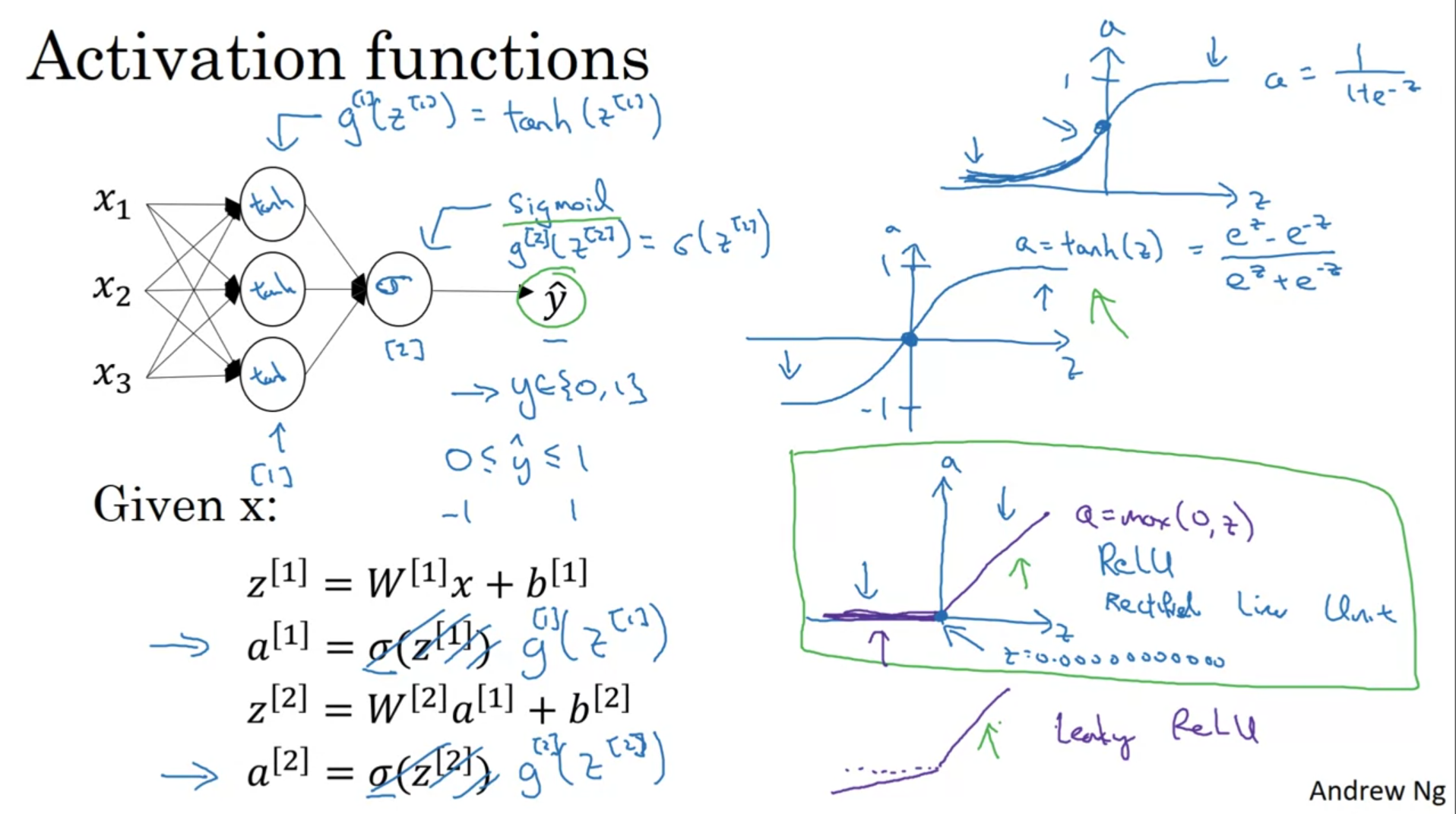
- binary classification taskları için last layerda sigmoid, hidden layerlarda ReLU kullan
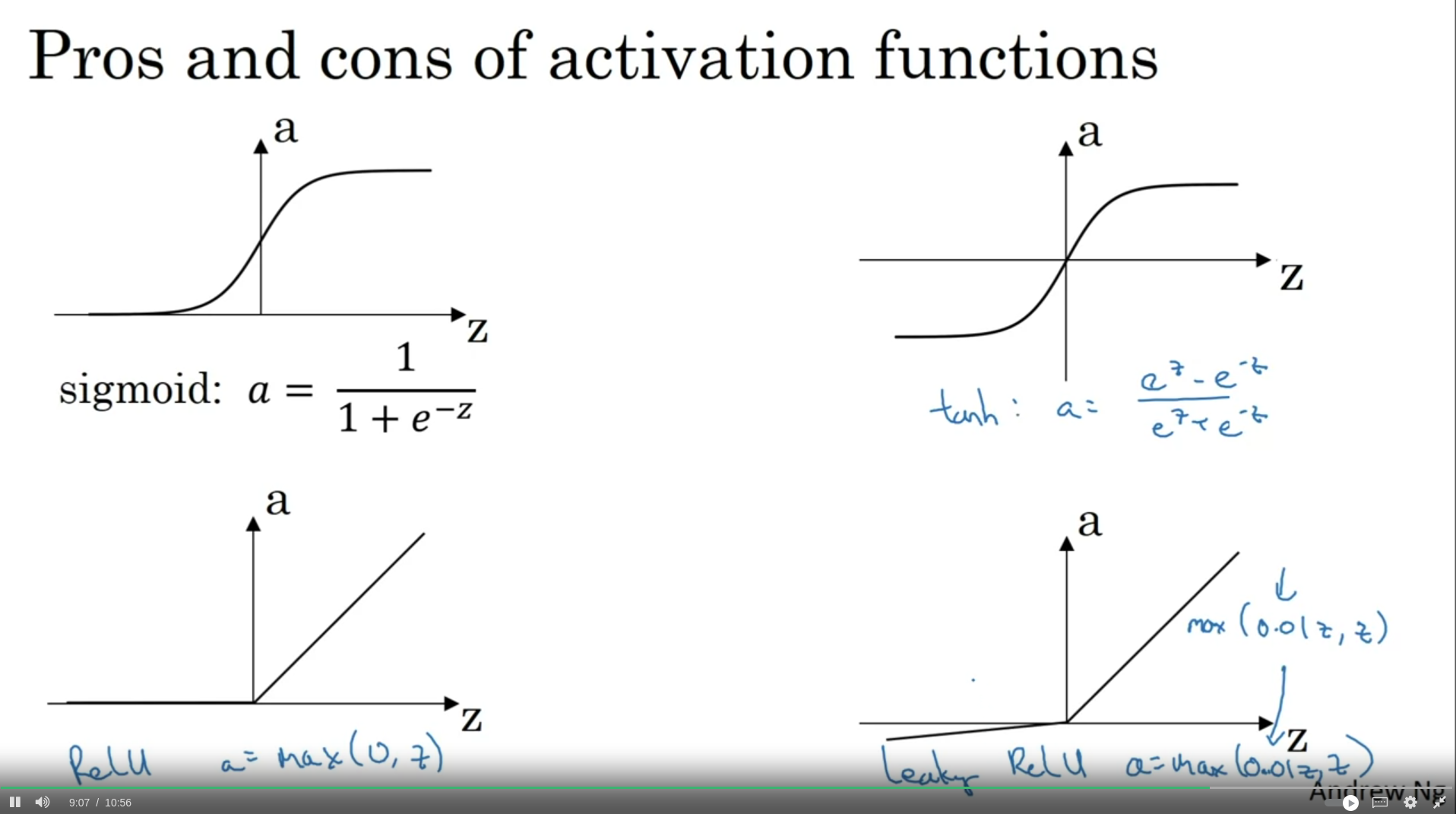
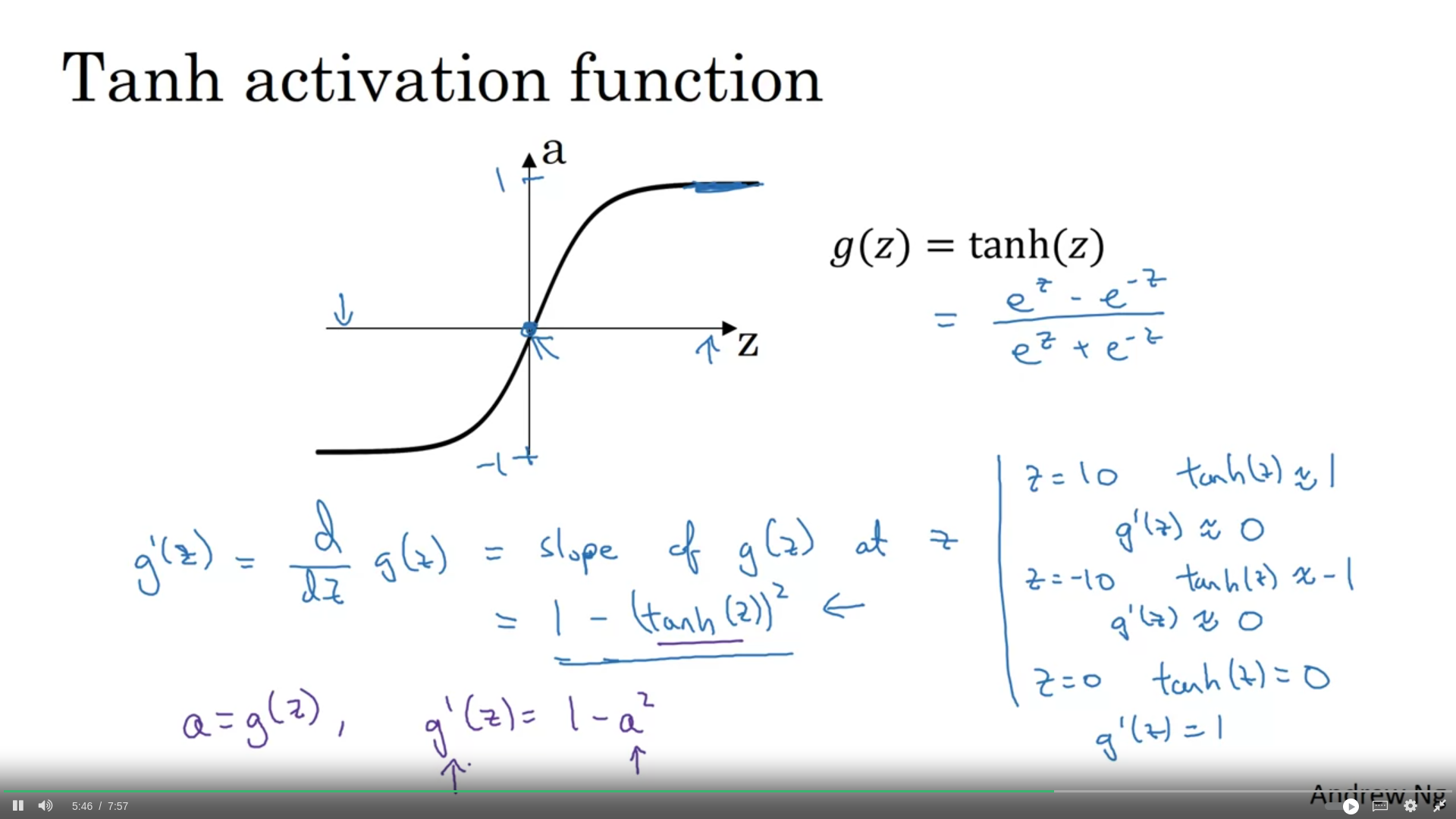
- almost never use sigmoid function except for last layer → for large and small values of x, learning is small since gradient becomes too small → tanh could be used instead
- ReLU a = max(0, z) veya leaky ReLU a = max(0.01z, z) kullan
- Linear activation function’ı 1 case hariç hiçbir yerde activation function olarak kullanmıyoruz çünkü linear activation function öğrenememeye sebep oluyor. Here is why:
- Linear activation function şu casede kullanılabilir:
- y is an element of Real number [-inf, inf]
- sadece output layerda linear activation olacak, hidden layerlarda ReLU, tanh vs olacak
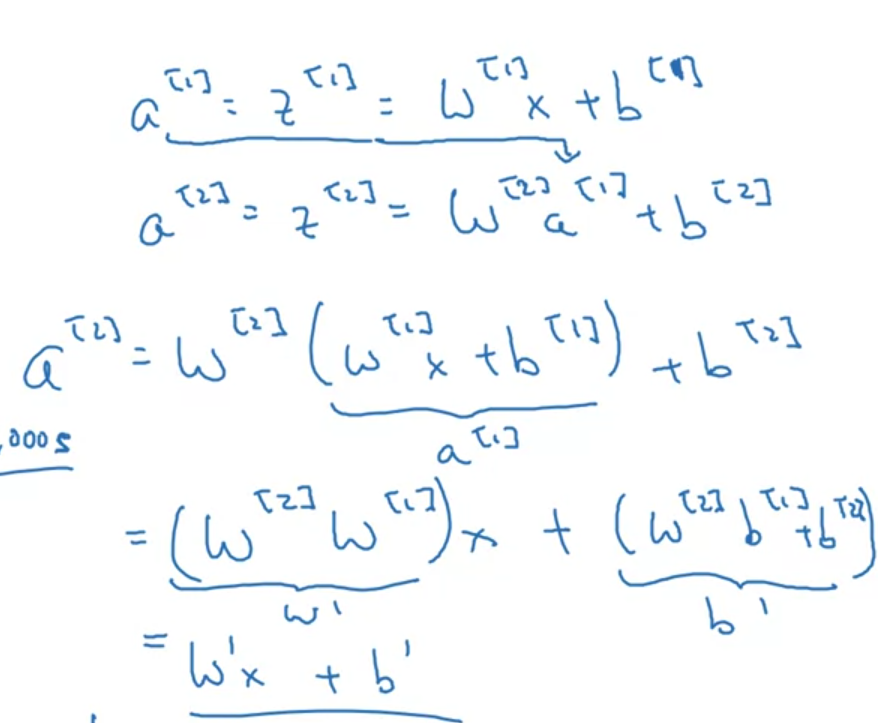
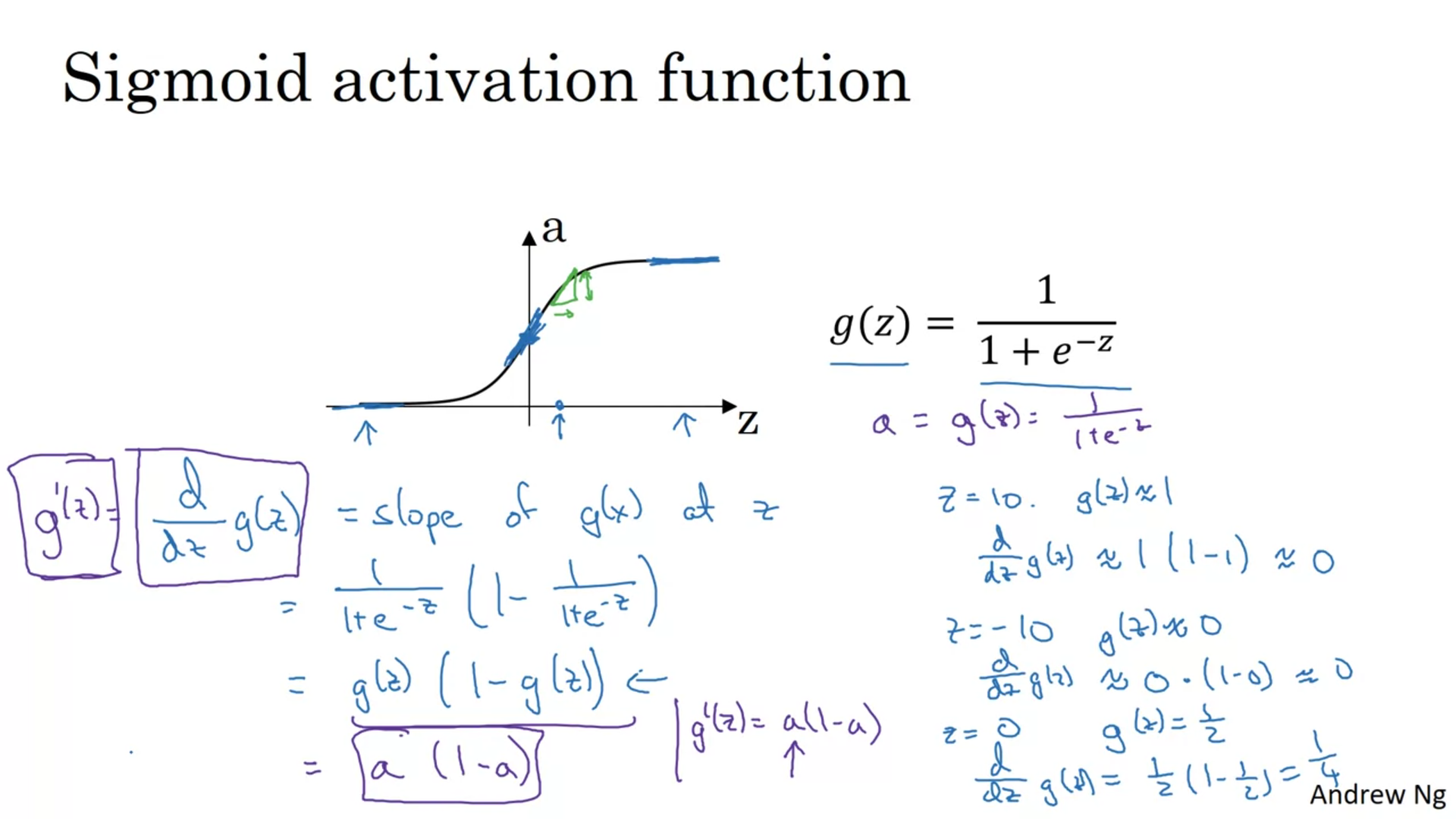





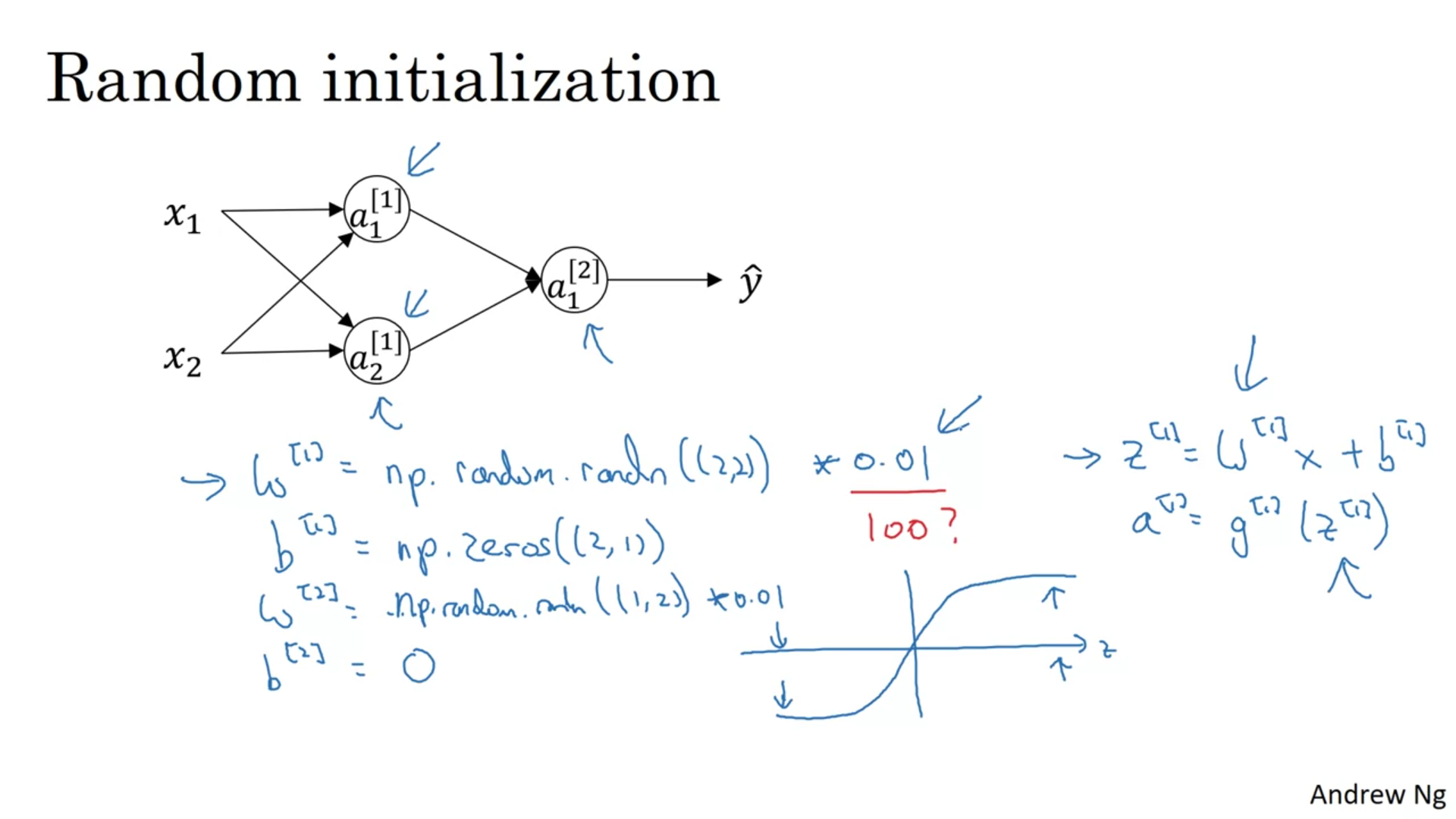
Do not initialize weights to 0 → no learning at all
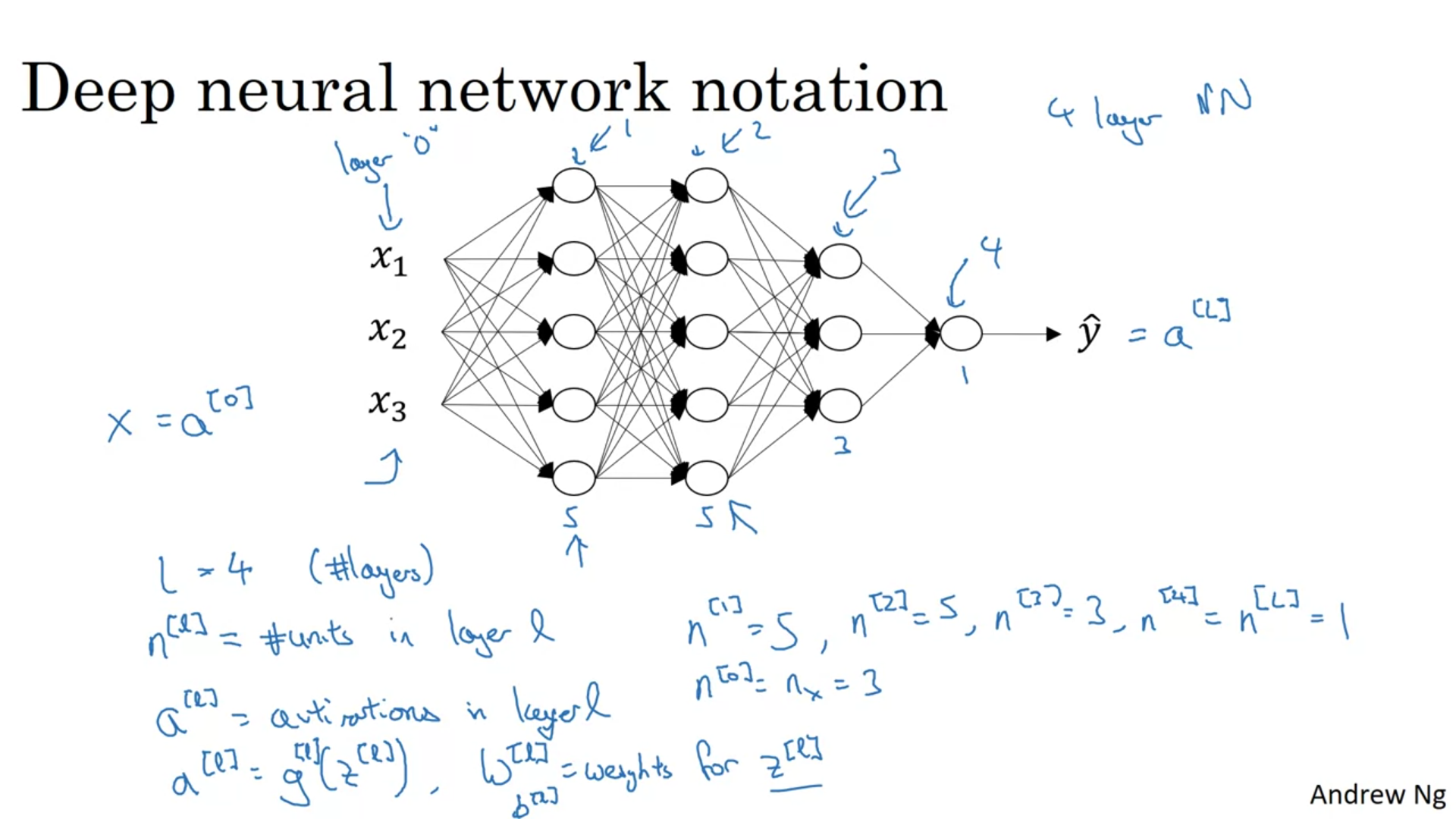
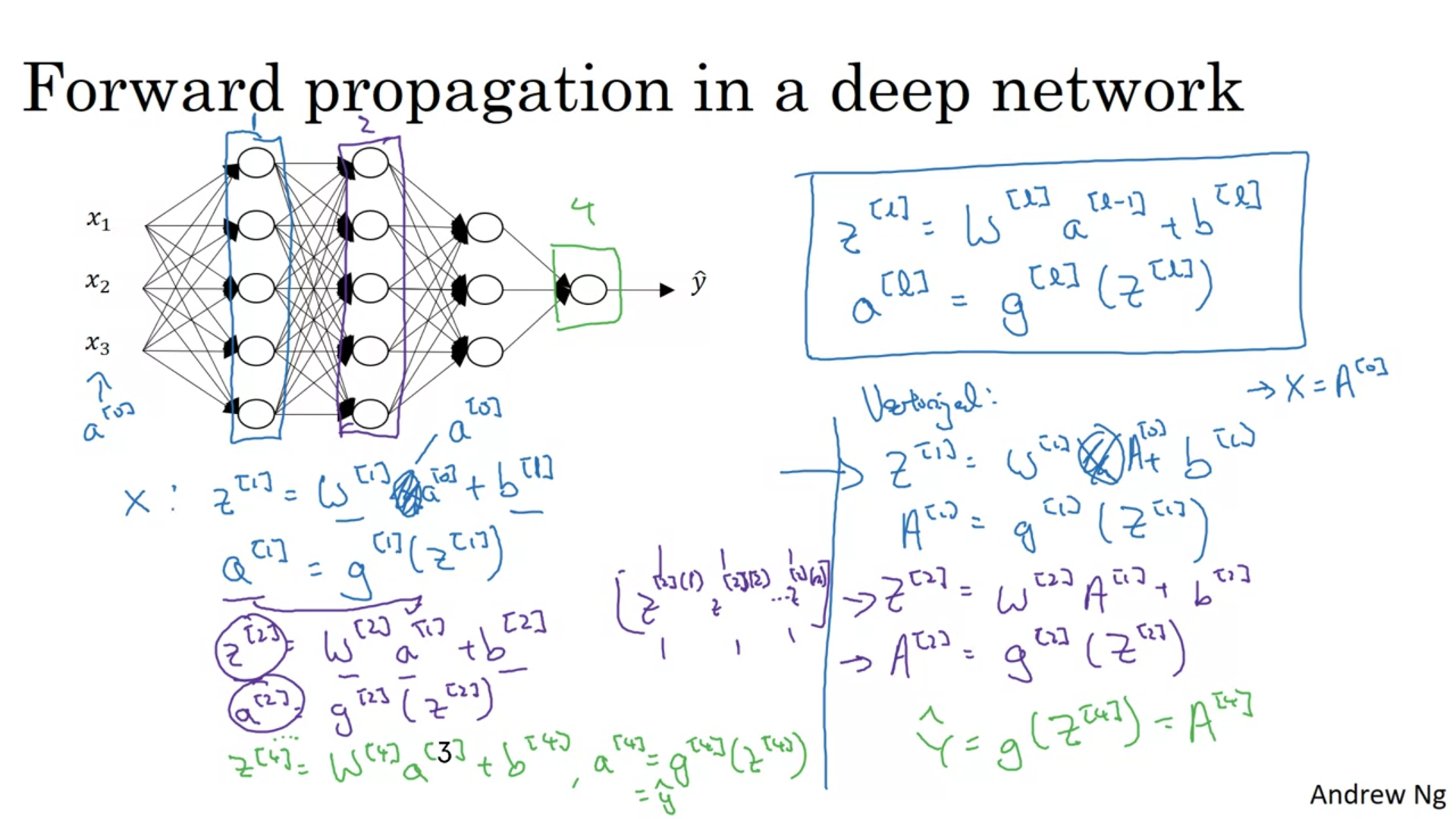
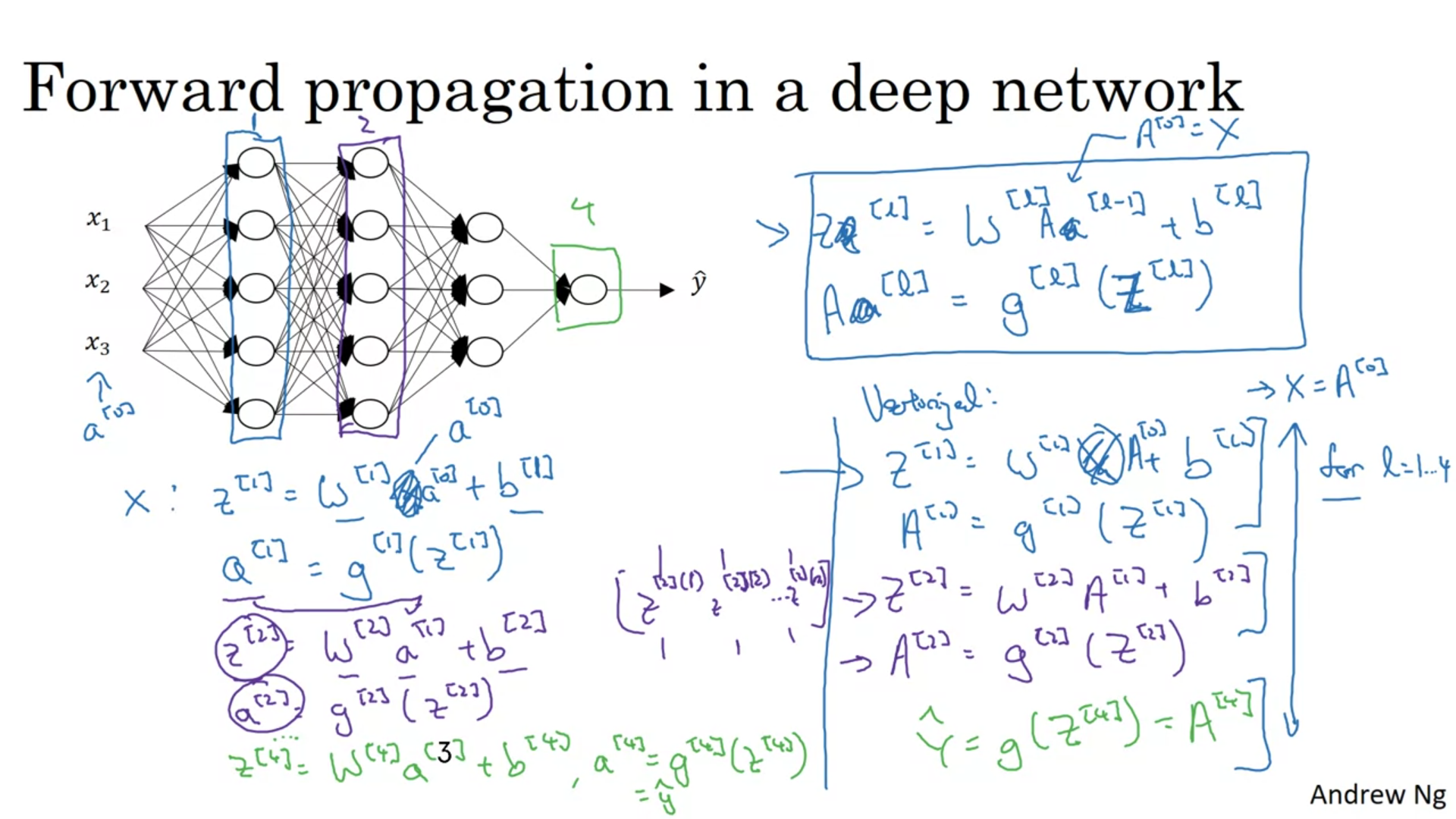
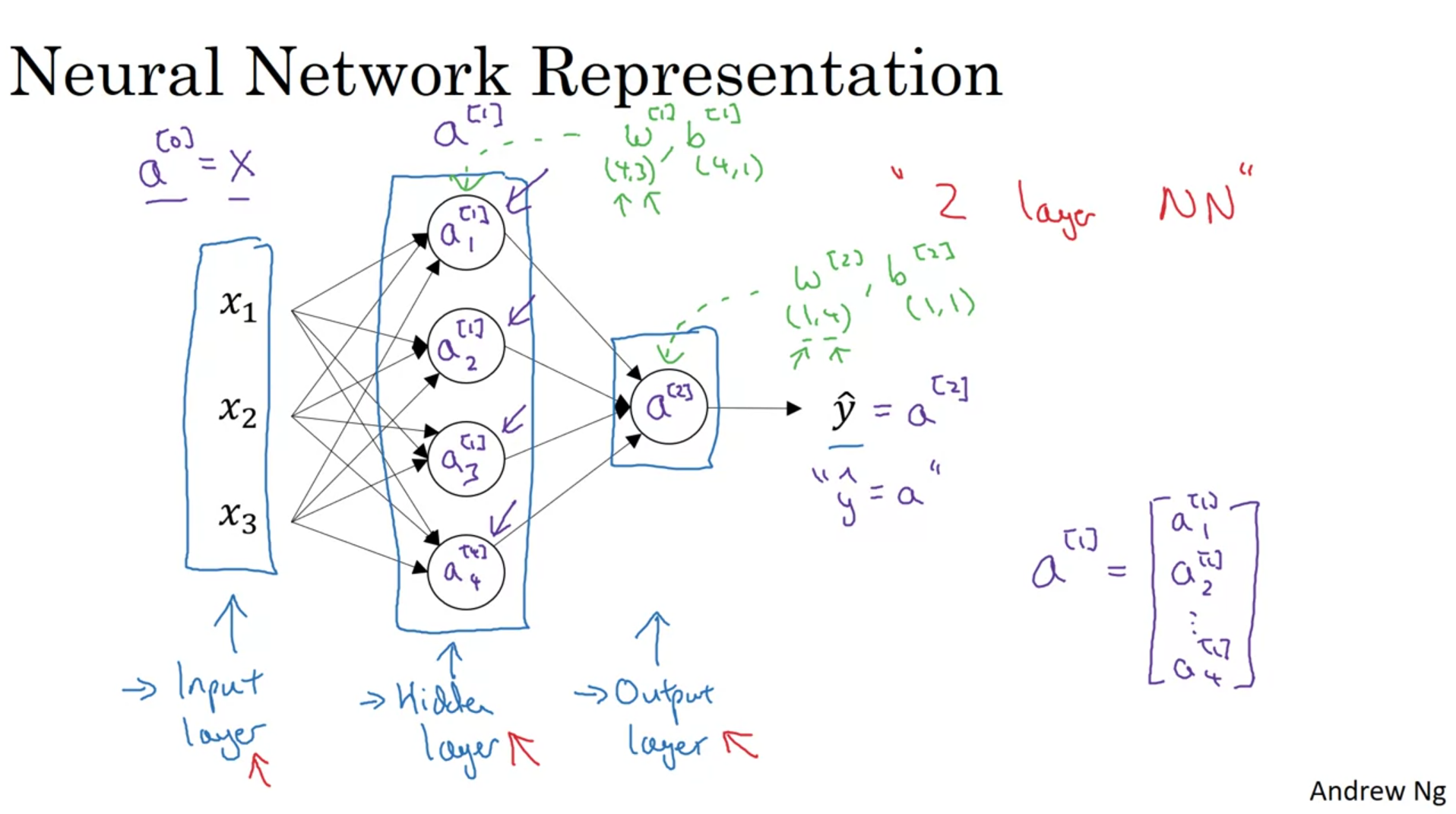
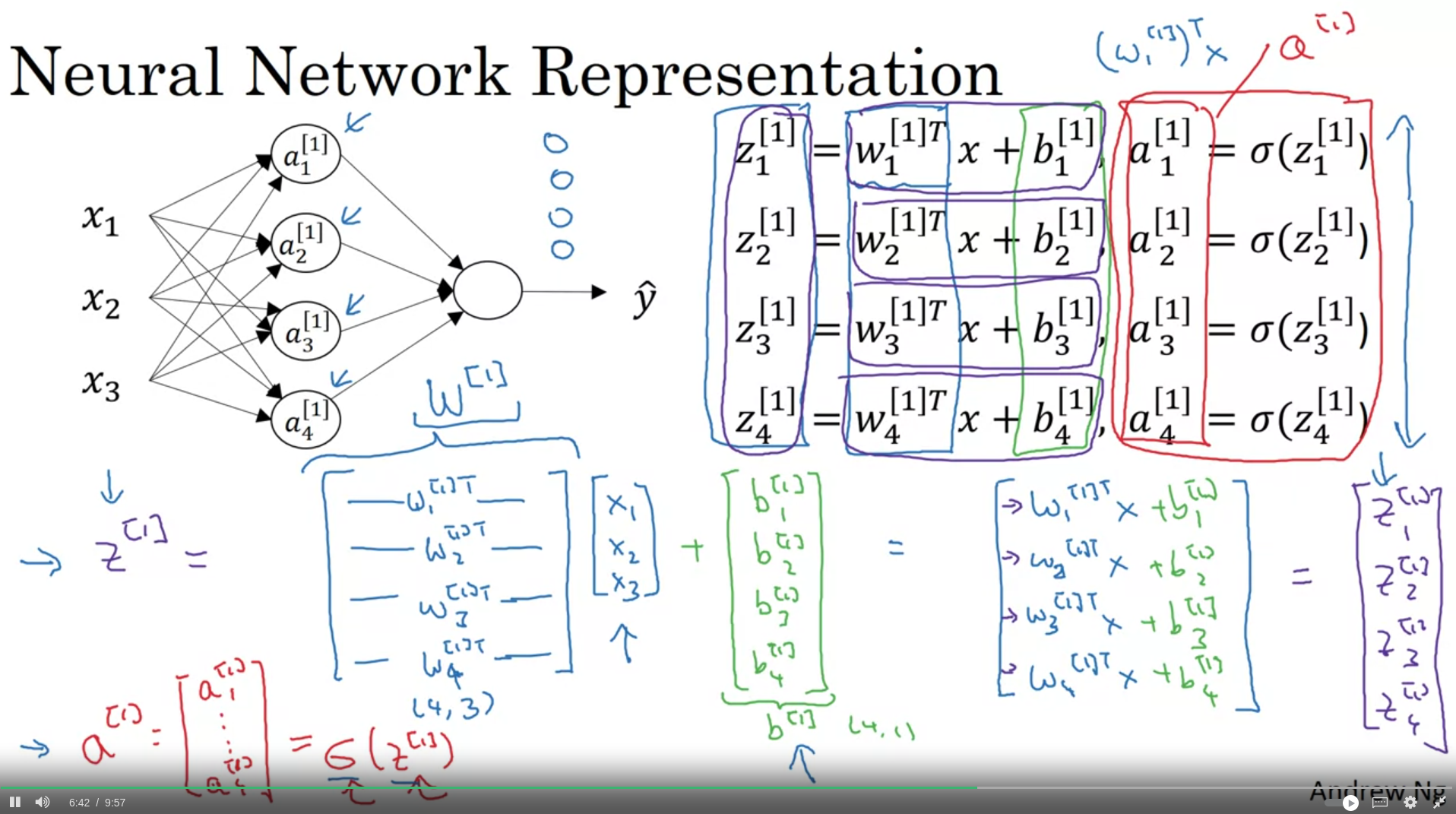
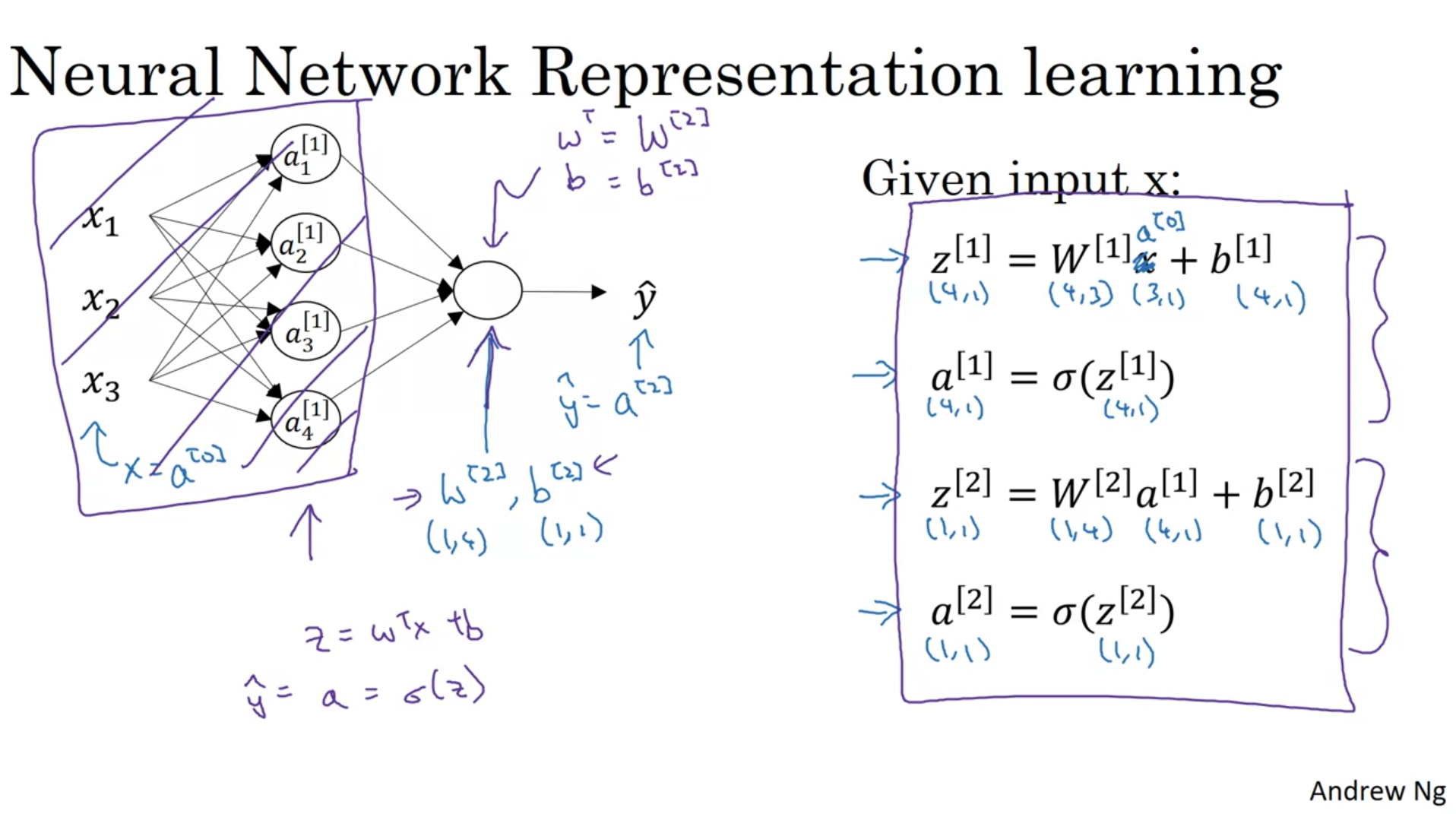
It is perfectly okey to have a for loop to calculate activation functions when there are more than one hidden layers.
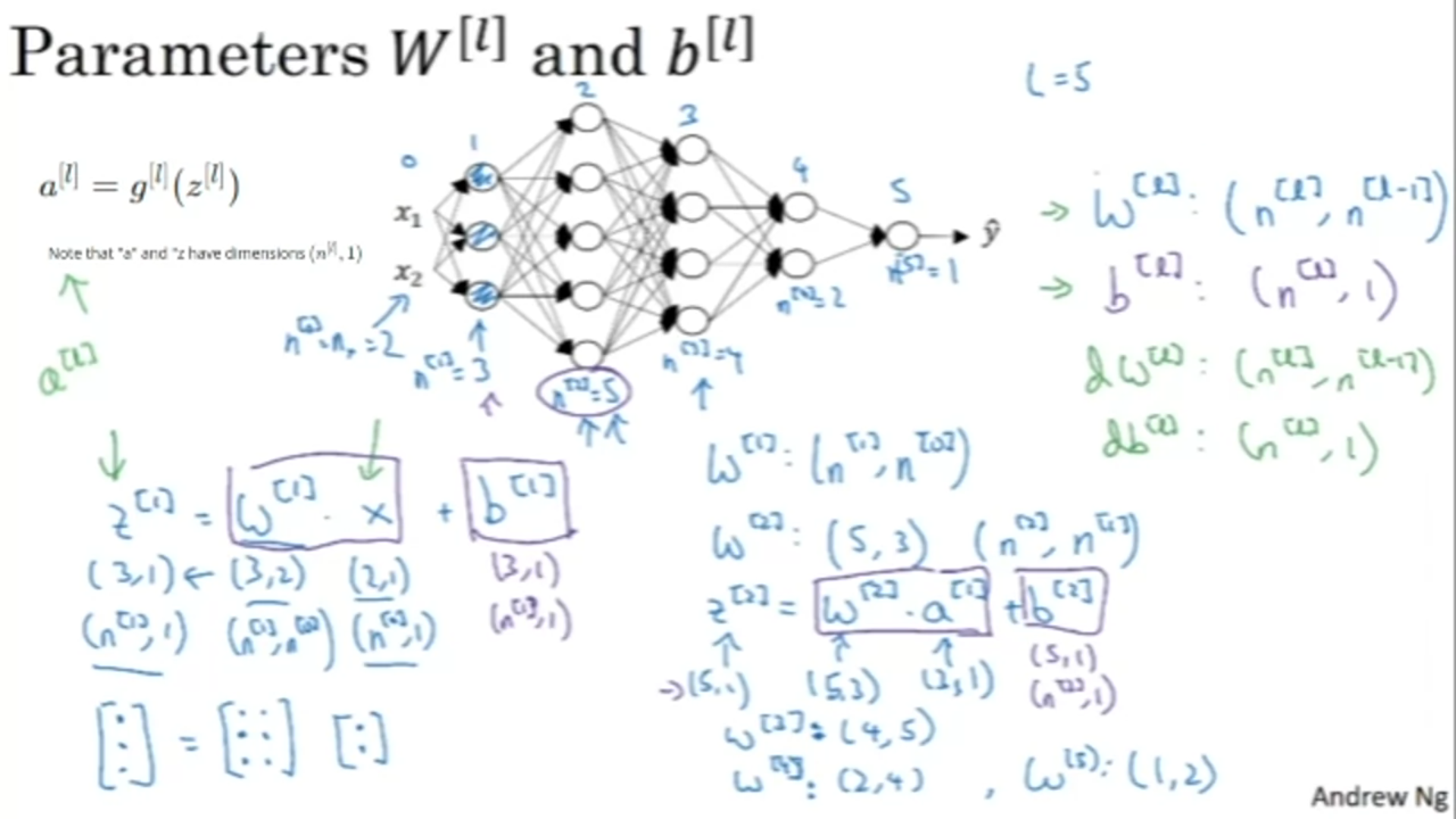
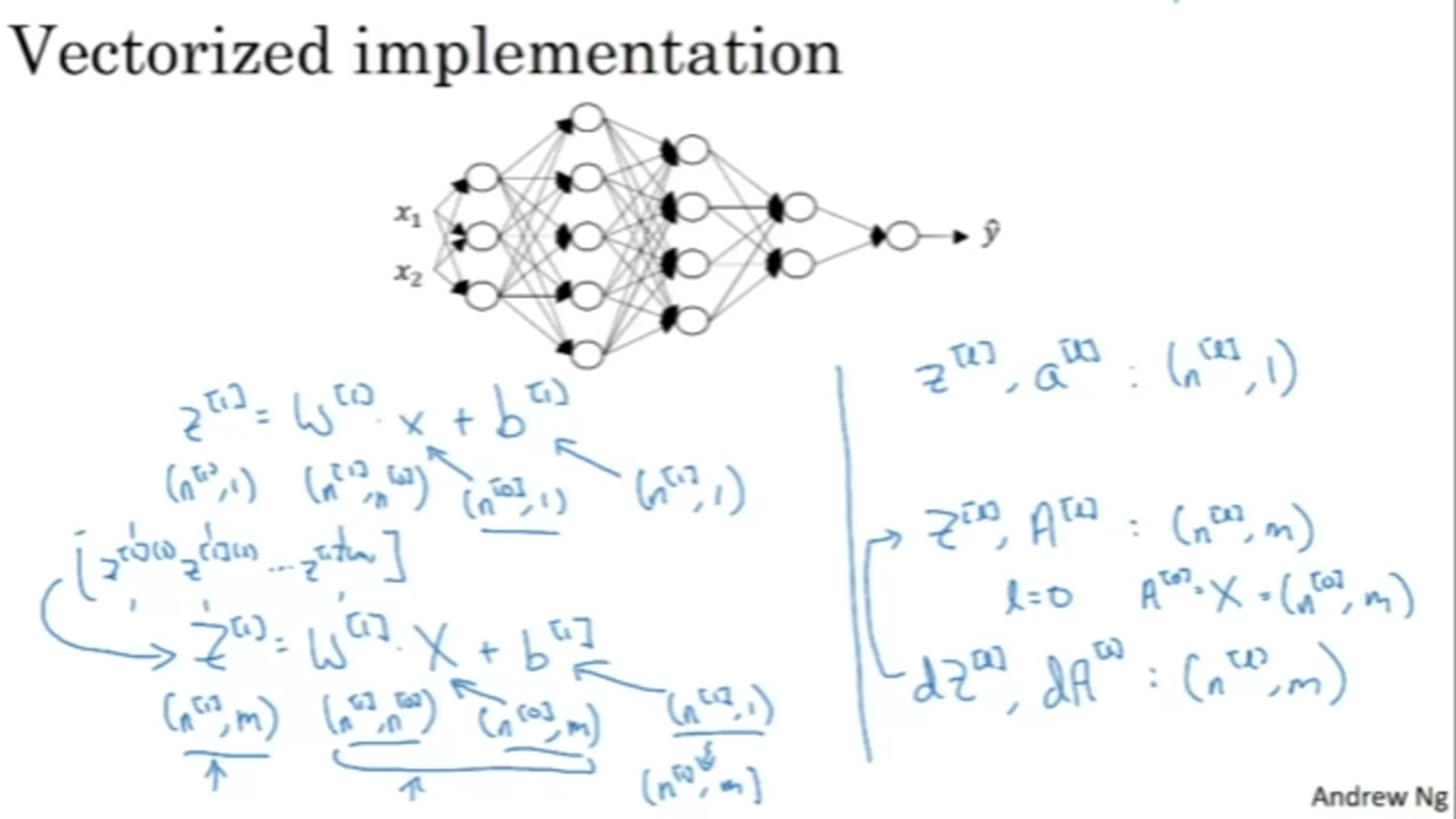
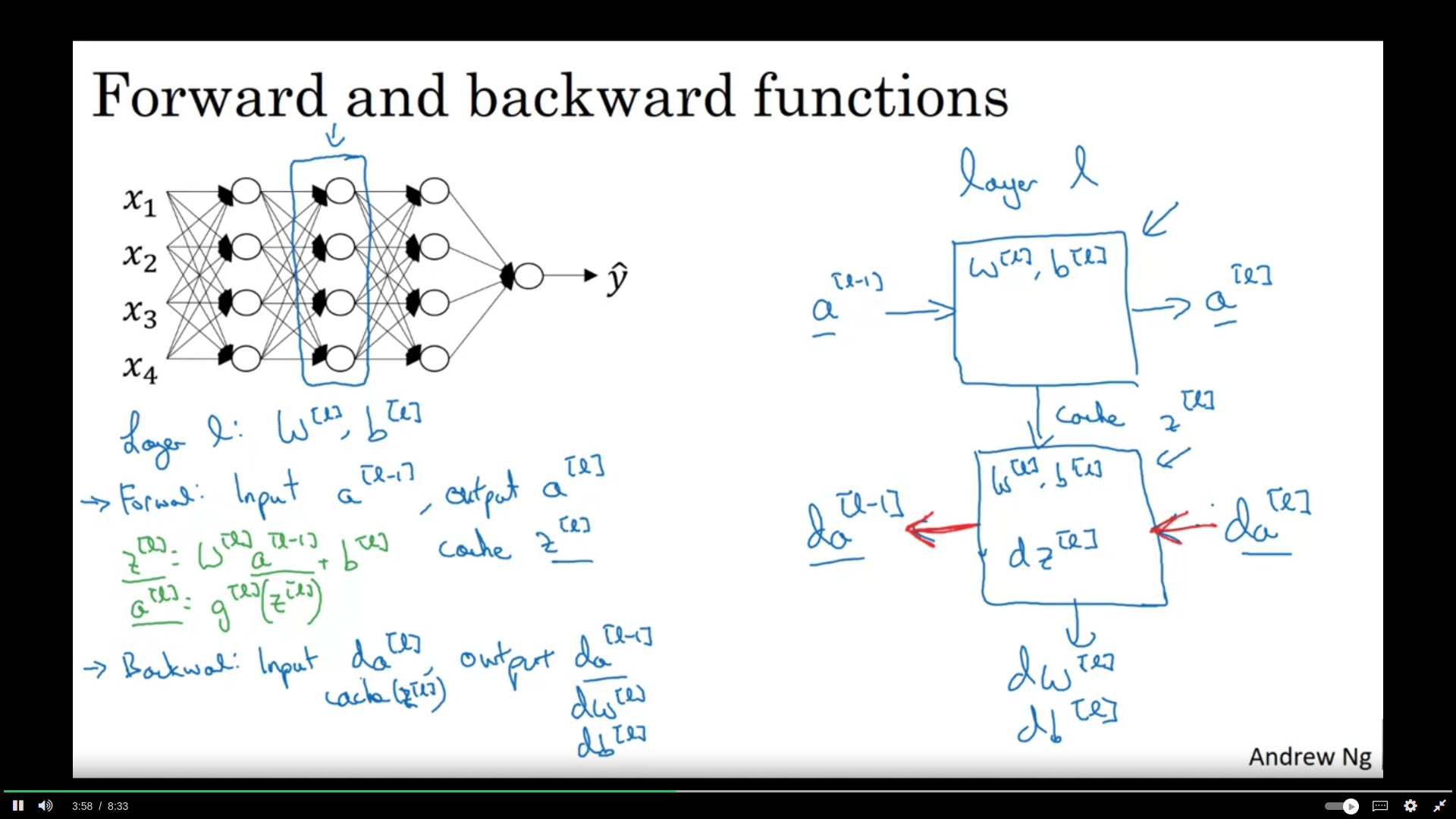
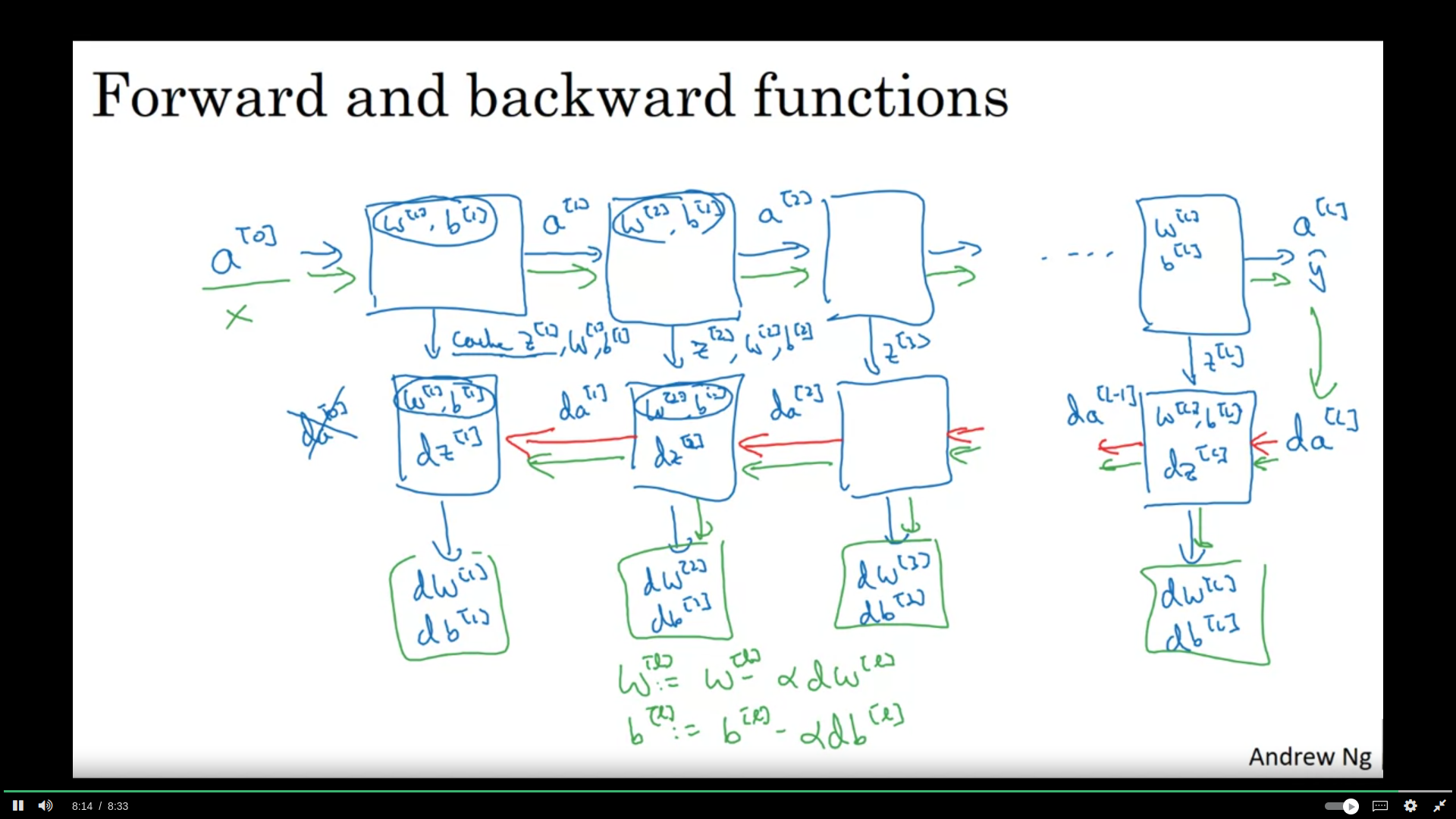
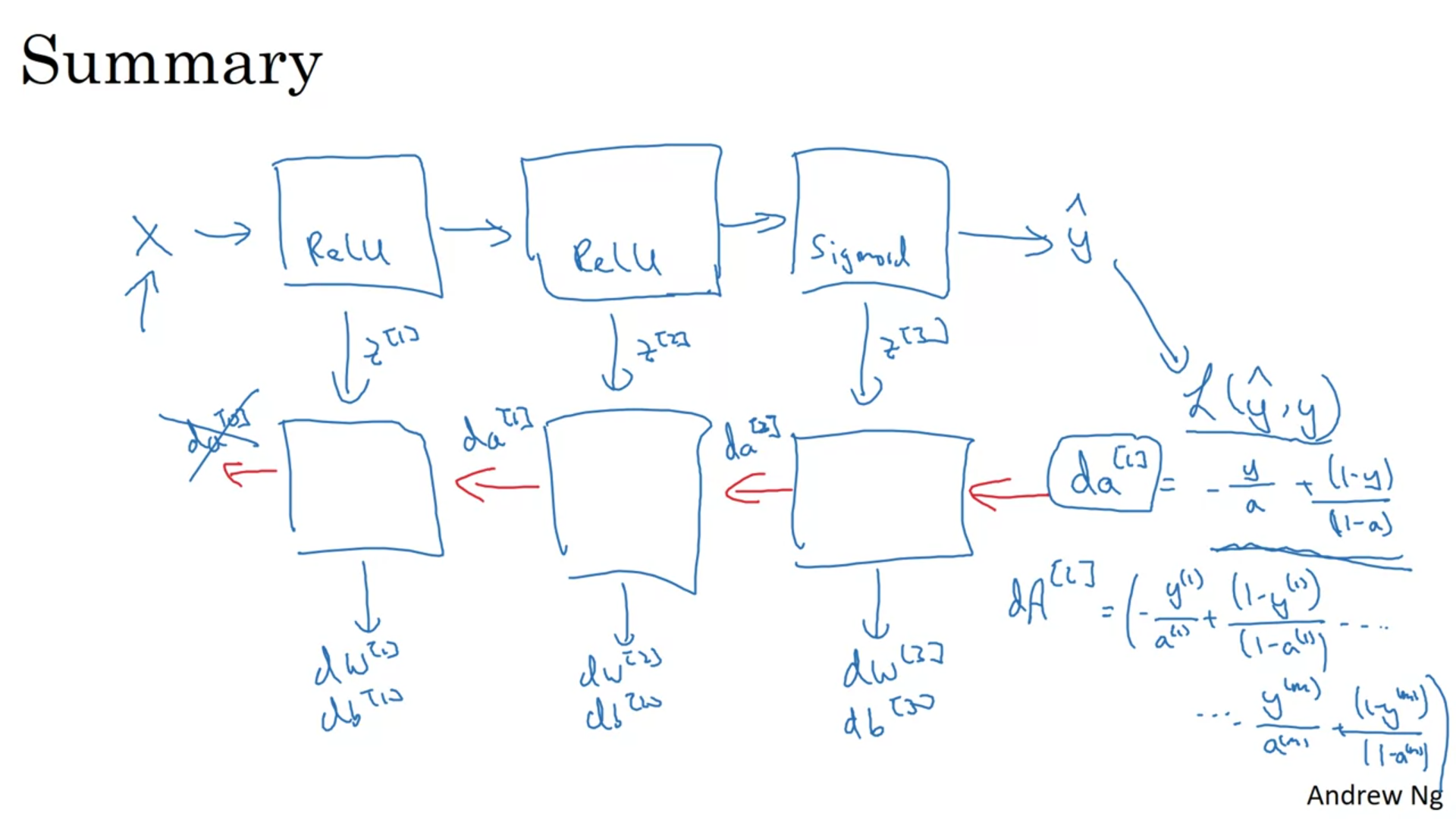
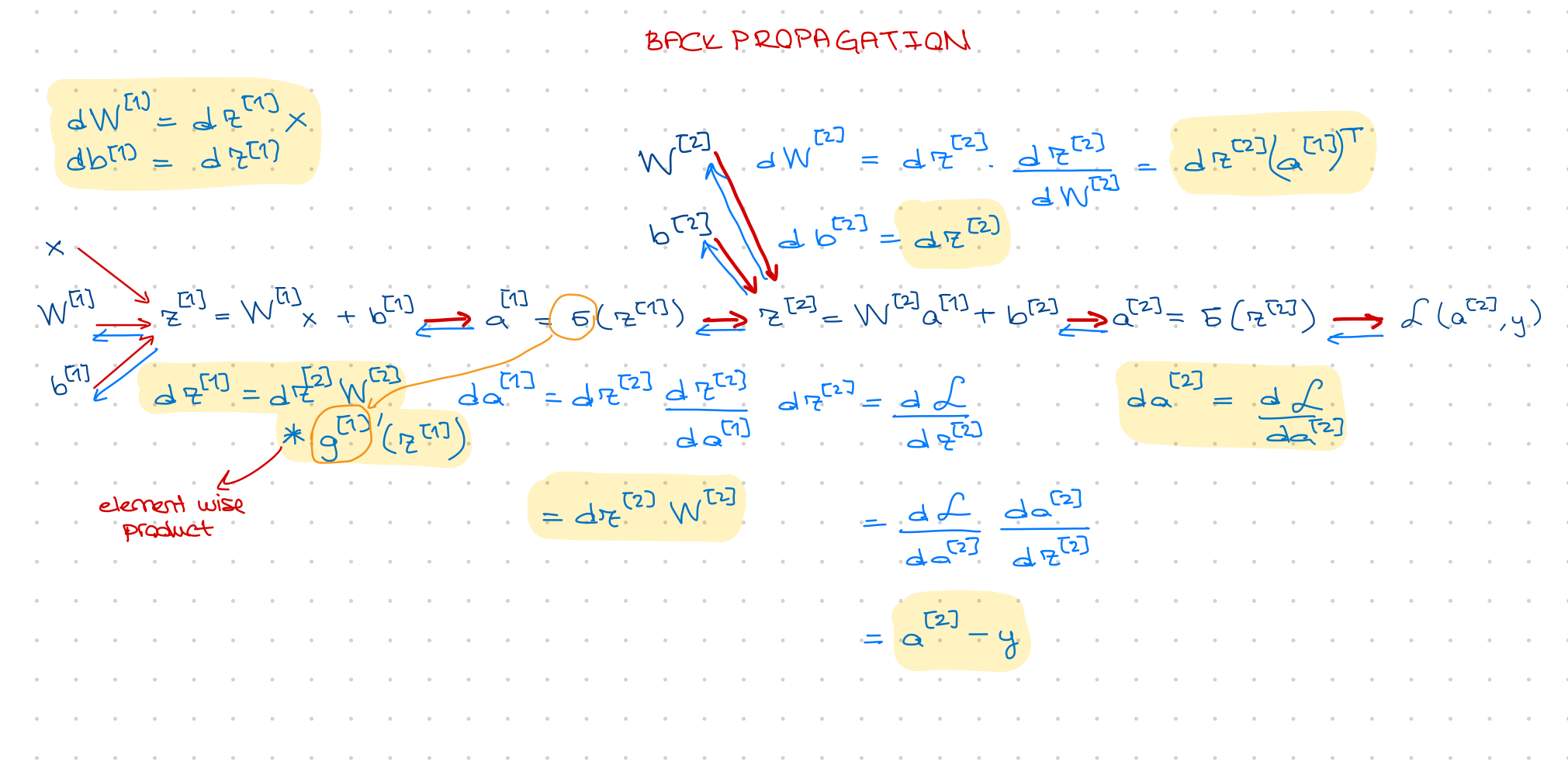
cache to be used in backward propagation