LLMs are few shot learners 4-lms_are_few_shot_learners.pdf , 6-Language_Models_are_Few-Shot_Learners.pdf
-
I skim through the paper. I especially get the idea of how gpt3 is trained with x-shot settings.
-
Figure 2.1 : How gpt3 is trained with zero-shot, one-shot, few-shot settings:
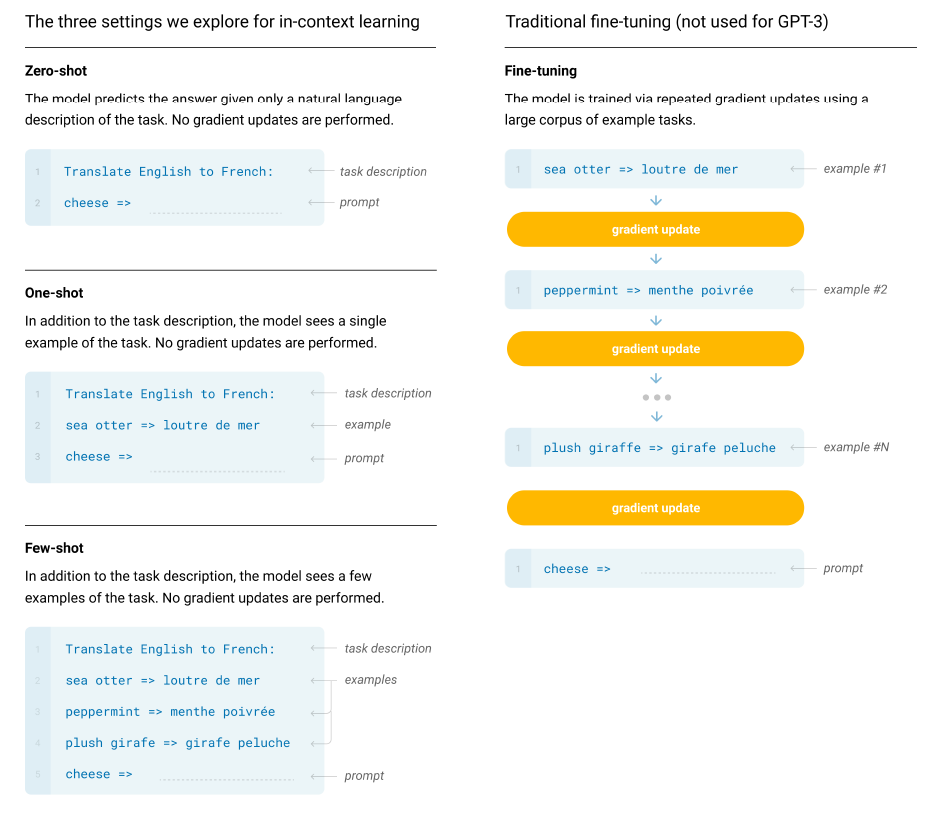
- Given:
- Task description
- One or more examples ( … → …)
- Prompt (… → ?)