Business Requirements
Örnek case: Kedi köpek sınıflandırması Kedi ve köpeklerin barınaklarda girdikleri klübeler var. Köpek klübesi köpek görünce kapısı açılıyor. Kedi görünce açılmıyor. Kedi klübesi kedi görünce kapısı açılıyor. Köpek görünce açılmıyor.
business gereksinimleri ile bilimsel yaklaşımı birleştiren veri bilimcisi oluyor.
ML system users: kullanıcılar, stakeholders burada sadece sistemin yapılmasını isteyenler değil sistemi kullanabilecek herkesin düşünülmesi lazım → mesela barınaktan hayvan sahiplenecek kişiler vs
Peki nasıl bir başarı oranı aranıyor: %90 true positive isteniyor olabilir Sistemde nasıl bir başarı almamız gerektiğinin belirtilmesi lazım MEsela 1 sn de 20 frame forward pass edebiliyor olsun ve hepsinden %90 üstü accuracy alabilsin - 20fps %90 accuracy başarısı istenşyor olsun
İlk problem tanımı yapılmalı: Makine öğrenimine gereksinim yoksa kullanmayalım! İnsan bazlı kodlanabilir değilse zor bir problemdir → Makine öğrenmesi gerekebilir
Mesela bizim case’imizde problem bir sınıflandırma. Detection değil (localization bazlı değil) 1. Cat vs Dog classification 2. Cat vs Dog vs Other classification 3. Cat vs Other classification + Dog vs Other Classification
Artık neyle çözebileceğimize dair bir fikrimiz var
Infrastructure
Sistem hangi device üzerinde çalışacak Case: Mesela klübenin üzerinde çalışsın ama pahalı bir device olmasın diyor → edge device kullanımı Edge Development Onnx cihaz + tensorRT engine → python seviye kodu c ye çekiyor Quantization → gereksiz 0 lardan kurtulmak (compact) Pruning → gereksiz leaflerden kurtulmak
Data
Klübenin önünden bir kamerayla kedi köpek göreceksen internetten topladığın ışık vs gibi etkenler accuracy f1 düşürebilir. Bulduğun data bu yüzden önemli. Gerçek case’te nelerle karşılaşacağını düşünüp data bulman lazım.
Mümkünse alandan veri topla Veri toplamak için setup kurup data toplanır.
ML Algorithms
Transfer learning
Domain çok uzak değilse freeze edilecek layer sayısı çok az olmalı
Evaluation
Data evaluation Performance Evaluation Liability Evaluation → model performansının uçlarını test ediyor → çamur geldi kameraya, yağmur yağdı vs bu caselerde nasıl çalışıyor model → hiç görmediği türlerde nasıl çalışıyor model → modelin genellendirmesi hakkında bir fikir sahibi olmuş oluyoruz
Gerçek casete mesela fps yüksek ihtimal düşecek. O yüzden kendi deneylerinde hedef fps ten daha yükseğini hedeflemelisin
Bazı türleri çok iyi öğrenememiş olabilir → daha fazla data toplaman lazım Ya da kediye overfit edebilir → data sayısı balance lanmalı vs
Modelin nasıl iyileştirileceğine dair intuition kazanma
Deployment
Deep stream Nvidia versiyonuna dönüşüm TensorRT versiyouna dönüşüm
After Deployment - Monitoring
Continual Learning Userlar environemnt değiştirebilir Edge device’ın değişimleri bildirmesi lazım Kamera bozlması, çamr gelmesi vs Hata için bildirim göndermesi lazım Çok aşırı yağmurlu bir case’te sınfılandırma yapma diyebilirsin mesela Elle threshold koyulabilir
Modelin loglarına bakarak model performansını sürekli takip etmeliyiz. Modeli tekrar eğitmek gerekebilir Best practice: Son 3 ayda toplanan datayı kullanarak tekrar eğitebilirsin ama içine geçmişteki datasetinden de veri eklemelisin
Route LLM Mesela başta küçük bir model querylere cevap veriyor Bu küçük modelin errorlarını hızlı ölçebilen başka bir sistem var Error arttıysa daha büyük modelin querylere cevap vermesini sağlıyoruz
Geoffrey Hinton → deep learning babası ileriye gitmek istiyorsanız benden farklı düşünün
think out of the box önümüzdeki hafta çarşamba perşembe gibi çözümü üzerine konuşalım one vs. all üstüne konuş → çok güçlü bir makinemiz yok bir modelleme yapmaktan kaçınmaya çalış sınıflandırma tür sayısı sürekli artıyor hayvanlar arası etkileşim → anlık cinsi tahmin edilsin tek sefer para ödüycem sistemin yeni türleri öğrenebilmesini istiyorum yei türle ilgili al sana 300 fotoğraf
RAG yapısına bak sınıf boyuutnda kendisini güncelleyebilecek bir sistem tasarlamak istsek nasıl tasarlardık
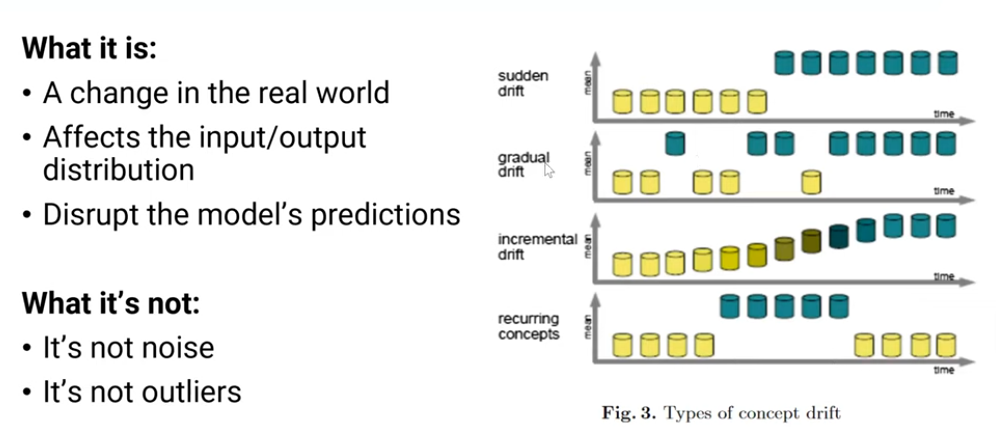
Concept Drift
Problems of each newcoming species: store costs grow linearly with new tasks
Class Incremental scenarios
ıncremental class learning
shared features with new classes

Incremental Learning to avoid catastrophic forgeting:
- Catastrophic Forgetting: The problem where the model forgets old knowledge when trained on new data.
- Replay Buffer: A subset of old data used during training with new data to mitigate catastrophic forgetting.
- Step 1: Train the Base Model Initially, train a model using the data for the 1000 species. This will serve as the starting point. Step 2: Fine-tuning with New Data When a new species arrives, fine-tune the model with the new data. This involves a few steps: 1. Data Preparation: Collect and preprocess 300 photos of the new species. 2. Data Augmentation: Increase the diversity of the new data using augmentation techniques (e.g., rotations, flips). 3. Replay Buffer: Maintain a small buffer of images from previously known species to train alongside the new species data. Managing Catastrophic Forgetting To prevent the model from forgetting previously learned species: 1. Replay Buffer: Always include a small subset of old data during training with new data. This helps the model retain its knowledge of old species. 2. Regularization Techniques: Use techniques like Elastic Weight Consolidation (EWC) which penalize large changes in the model weights to preserve old knowledge.