Jalammar Transformers Blogpost
- 6 encoder + 6 decoder
- Each encoder is the same in the structure yet they do not share weights
Steps
Given a sentence S = {}
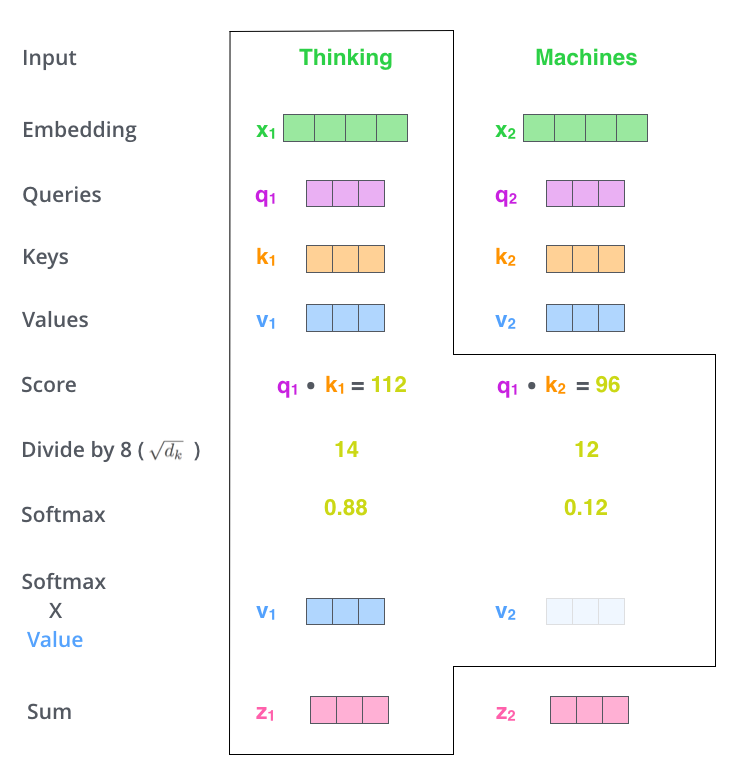
- Calculate vector embedding for each
- Sum with positional embedding =
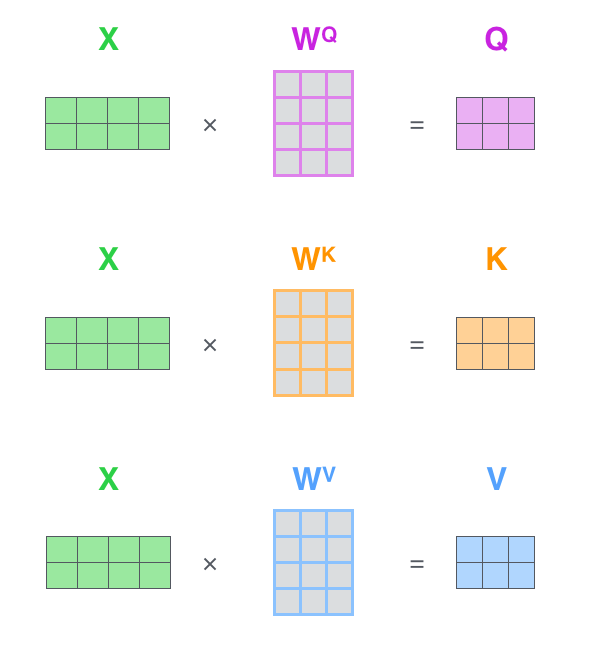
- Calculate query, key, value vectors for each
- Calculate score of each position by the following formula
- = Z
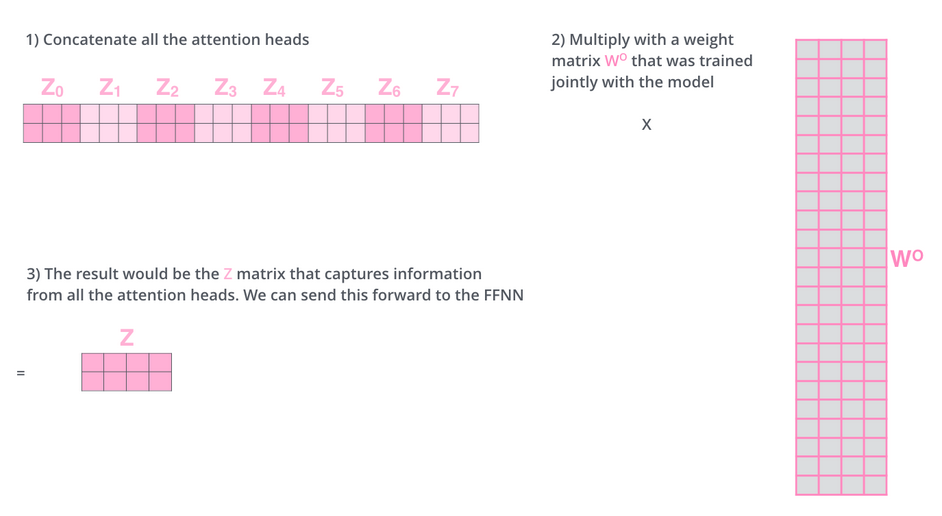
- Assume we applied all above in a multi-head attention manner with 8 heads. We will obtain 8 different Z matrices. We concat them and multiply with an additional weight matrix
- Transform last encoders output into K and V and feed into each of the decoders.
- Using the K and V first cycle produces and output. After the first cycle, each cycle begins with the previous output. Decoding phase ends when EOS token is produced.
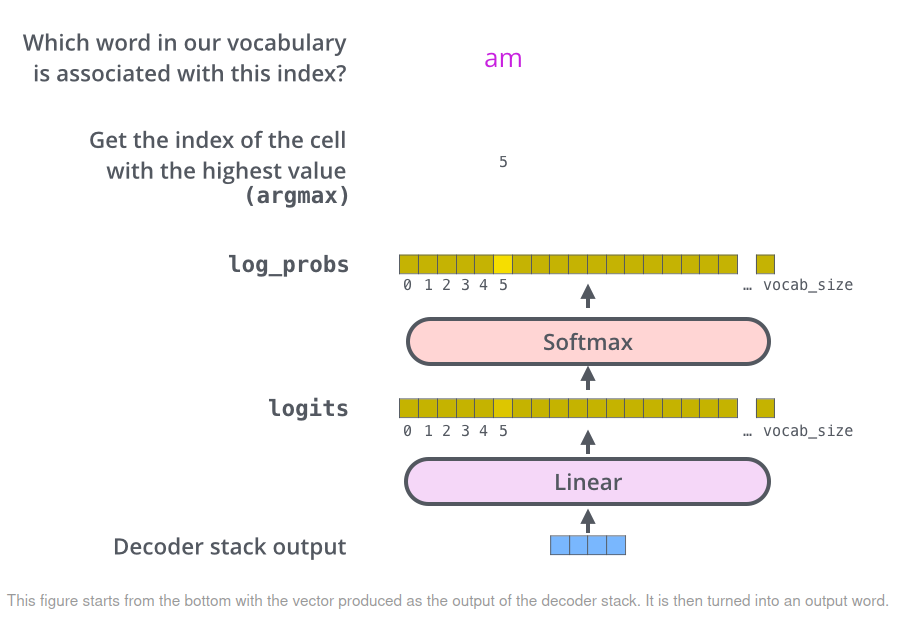
- The last layer of decoder outputs a vector of floats of size 1x512. The linear layer and softmax function at the end produces a huge logits vector of size our vocabulary. The cell with the highest probability is chosen to be the corresponding word.