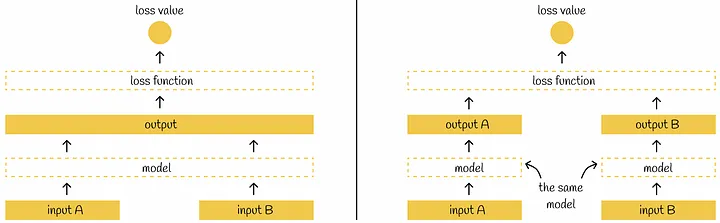
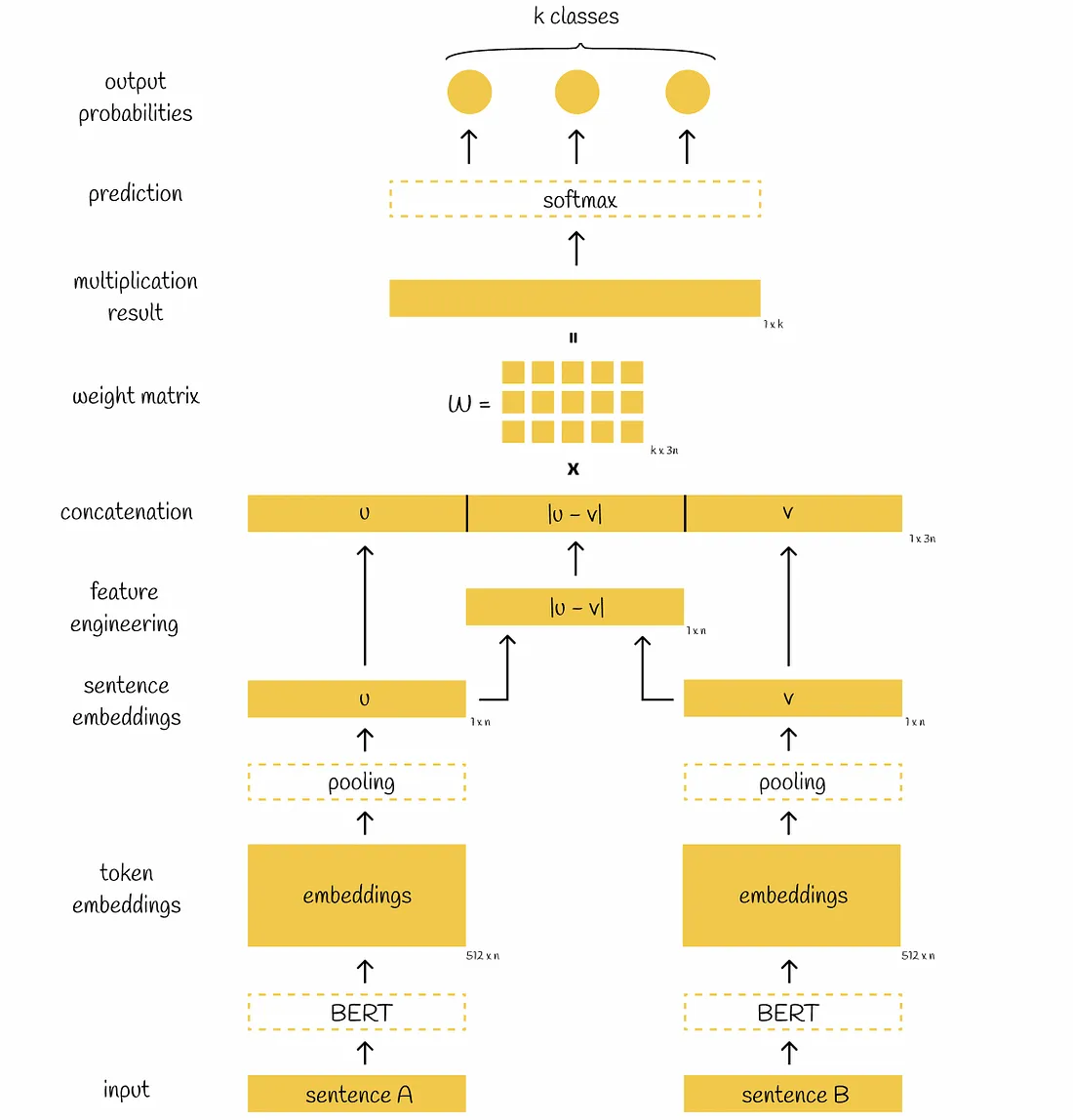
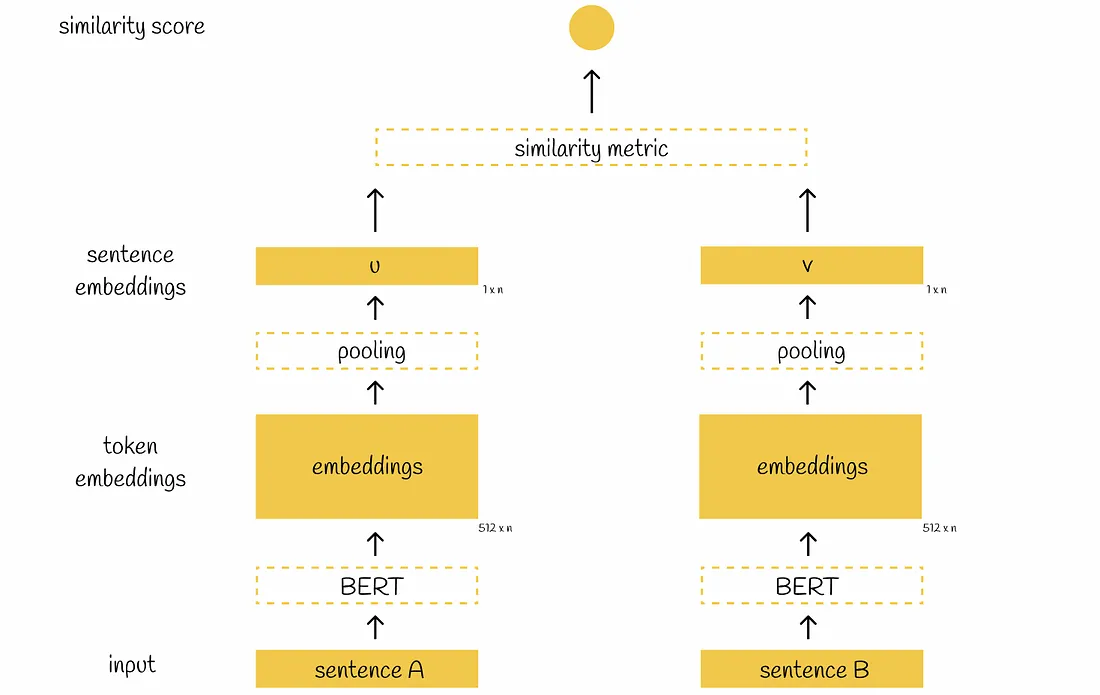
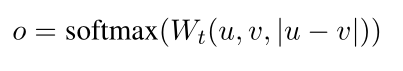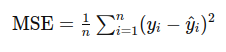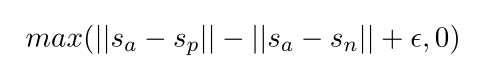SBERT adds a pooling operation to the output of BERT / RoBERTa to derive a fixed sized sentence embedding.
Non-Siamese (cross-encoder) architecture is shown on left, and the Siamese (bi-encoder) architecture is on the right. The principal difference is that on the left the model accepts both inputs at the same time. On the right, the model accepts both inputs in parallel, so both outputs are not dependent on each other.
Objective Functions
Classification Objective
Finally, three vectors u, v and |u-v| are concatenated, multiplied by a trainable weight matrix W and the multiplication result is fed into the softmax classifier which outputs normalised probabilities of sentences corresponding to different classes.
The cross-entropy loss function is used to update the weights of the model.
ask burada nasıl labellar verdiklerini göremedim. Yani NLI gibi mi incelemişler burayı it follows it does not follow vs gibi?
Regression Objective Function
In this formulation, after getting vectors u and v, the similarity score between them is directly computed by cosine similarity.
The predicted similarity score is compared with the true value and the model is updated by using the MSE loss function.
ask şimdi burada loss hesaplarken predicted value true value ile karşılaştırılıyor diyor. True value yu nereden buluyoruz?
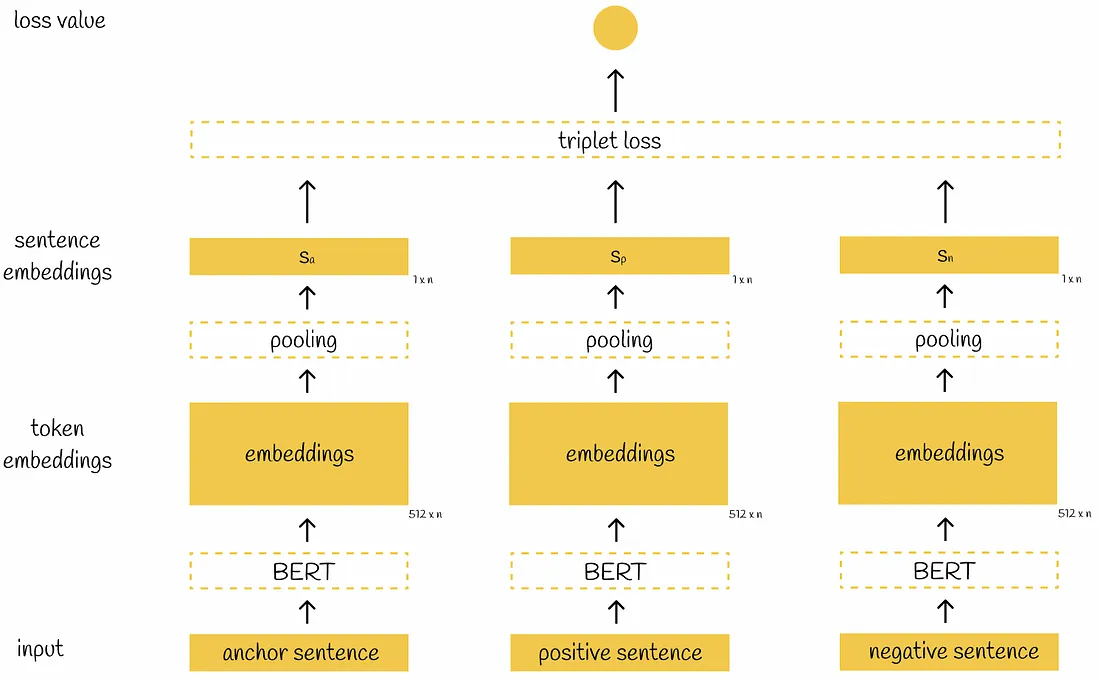
Triplet Objective Function
The triplet objective introduces a triplet loss which is calculated on three sentences usually named ==anchor==, positiveandnegative====.
It is assumed that anchor and positive sentences are very close to each other while anchor and negative are very different.
During the training process, the model evaluates how closer the pair ==(anchor, positive) is, compared to the pair (anchor, negative)====.
The triplet SBERT architecture differs from the previous two in a way that the model now accepts in parallel three input sentences (instead of two).