-
[ ]
-
Tokenizer: We use the same tokenizer as Llama 1; it employs a bytepair encoding (BPE) algorithm (Sennrich et al., 2016) using the implementation from SentencePiece (Kudo and Richardson, 2018). As with Llama 1, we split all numbers into individual digits and use bytes to decompose unknown UTF-8 characters. The total vocabulary size is 32k tokens.
-
GQA: grouped-query-attention
- tüm kelimelere tek tek bakmak yerine kelimeleri öncesinde gruplayıp sadece istediğim grupla alakalı olan kelimelerde attention arıyorum
LLama2 ve LLama1 arasındaki farklar
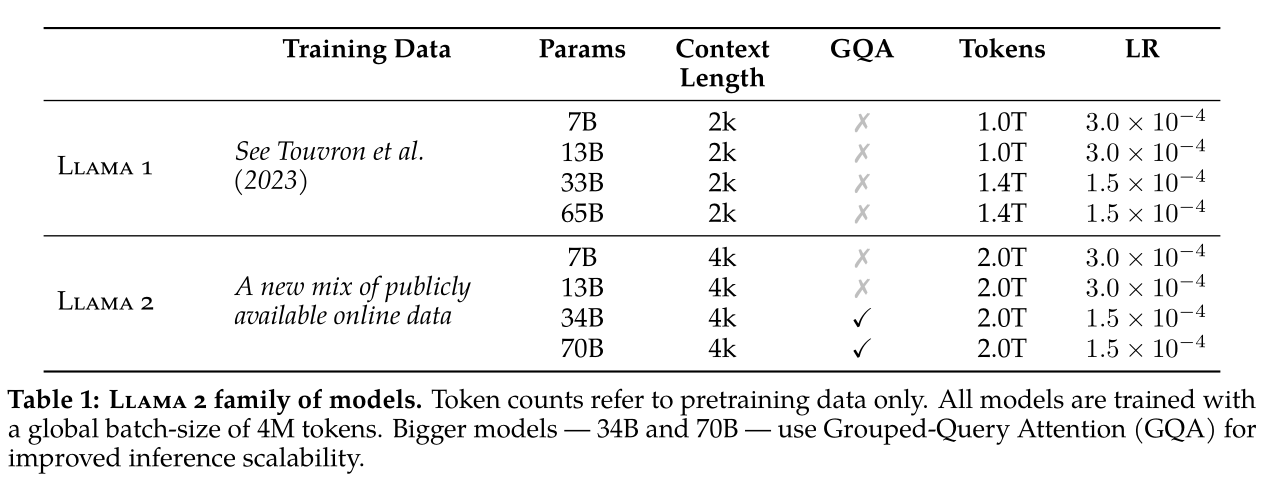
- We use the standard transformer architecture (Vaswani et al., 2017), apply pre-normalization using RMSNorm (Zhang and Sennrich, 2019), use the SwiGLU activation function (Shazeer, 2020), and rotary positional embeddings (RoPE, Su et al. 2022). The primary architectural differences from Llama 1 include increased context length and grouped-query attention (GQA).
- Specifically, we performed more robust data cleaning, updated our data mixes, trained on 40% more total tokens, doubled the context length, and used grouped-query attention (GQA) to improve inference scalability for our larger models.
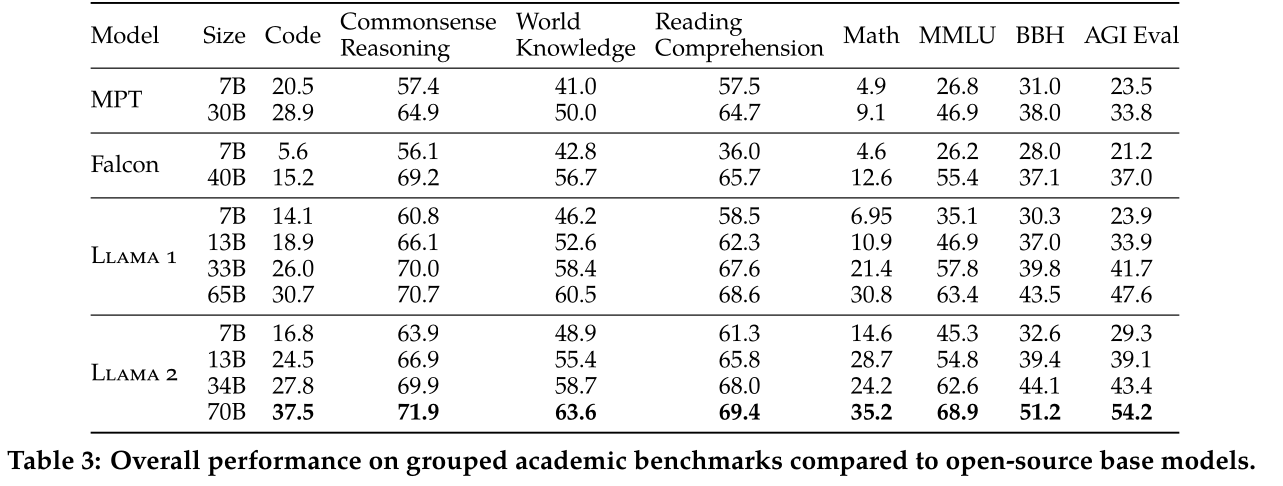
Llama1 ve Llama2 karşılaştırma
LLama2 Chat
SFT Supervised Fine Tuning
- Instruction tuning + RLHF
- Supervised fine-tuning + reward modeling + RLHF + Ghost Attention (GAtt)
- Fine-Tuning Details. For supervised fine-tuning, we use a cosine learning rate schedule with an initial learning rate of 2 × 10−5 , a weight decay of 0.1, a batch size of 64, and a sequence length of 4096 tokens.
- For the fine-tuning process, each sample consists of a prompt and an answer. To ensure the model sequence length is properly filled, we concatenate all the prompts and answers from the training set. A special token is utilized to separate the prompt and answer segments. We utilize an autoregressive objective and zero-out the loss on tokens from the user prompt, so as a result, we backpropagate only on answer tokens. Finally, we fine-tune the model for 2 epochs.
- Backpropagate Only on Answer Tokens: Backpropagation is the process used to update the model’s weights based on the loss. By ignoring the loss on the user prompt tokens, they ensure that the model’s weights are updated only based on the errors made in generating the response (answer tokens). This means that the model learns to improve its responses rather than the way it processes the prompts.
- We found that SFT annotations in the order of tens of thousands was enough to achieve a high-quality result.
Reinforcement Learning with Human Feedback (RLHF)
- RLHF is a model training procedure that is applied to a fine-tuned language model to further align model behavior with human preferences and instruction following.
- Human annotators select which of two model outputs they prefer. This human feedback is subsequently used to train a reward model, which learns patterns in the preferences of the human annotators and can then automate preference decisions.
- Human Preference Data Collection
- Reward için binary comparison protocol uygulanıyor
- Annotator bir prompt yazıyor ve farklı iki modelin ürettiği cevaplardan birini seçmesi isteniyor. Seçtiği model response’u ne derece diğerine üstün bulduğunu belirtiyor: significantly better, better, slightly better, or negligibly better/ unsure
- Reward Model
- Input: Model response + prompt
- Output: Scalar score to indicate quality (Helpfulness and safety )
- Observation → the two of them are hard to catch together
- Reward model weightleri pretrained chat model checkpointinden initalize etmişler
- Reward model chat modeli ne bilirse bilyior
- Böyle information mismatch olmayacak → hallucinationlar engellenmiş oluyor
- Loss function:
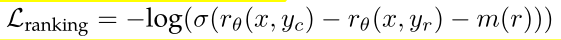
- “we convert our collected pairwise human preference data into a binary ranking label format (i.e., chosen & rejected) and enforce the chosen response to have a higher score than its counterpart.”
- rθ (x, y): is the scalar score output for prompt x and completion y with model weights θ.
- yc: the preferred response that annotators choose
- yr: the rejected counterpart.
- m(r): the margin, a discrete function of the preference rating.
- Naturally, we use a large margin for pairs with distinct responses, and a smaller one for those with similar responses
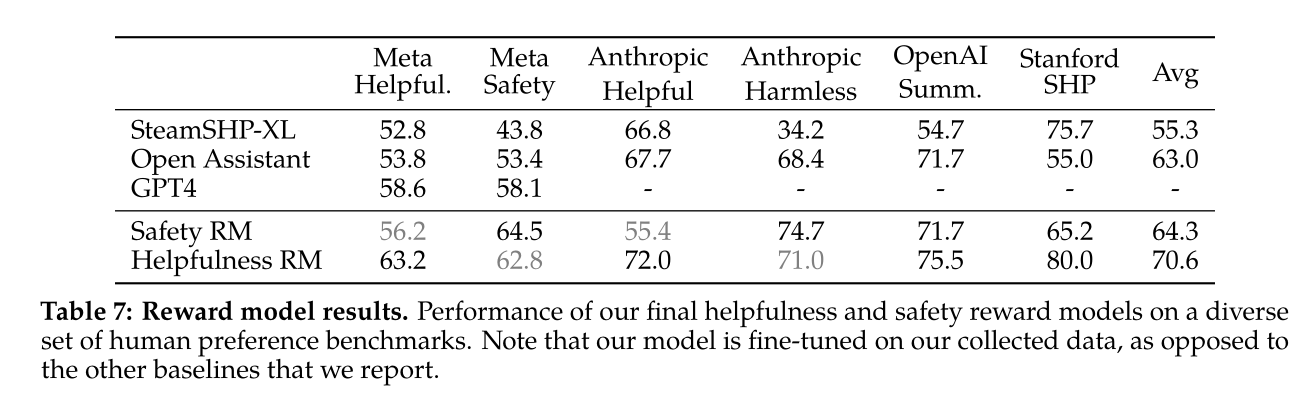
- Results:
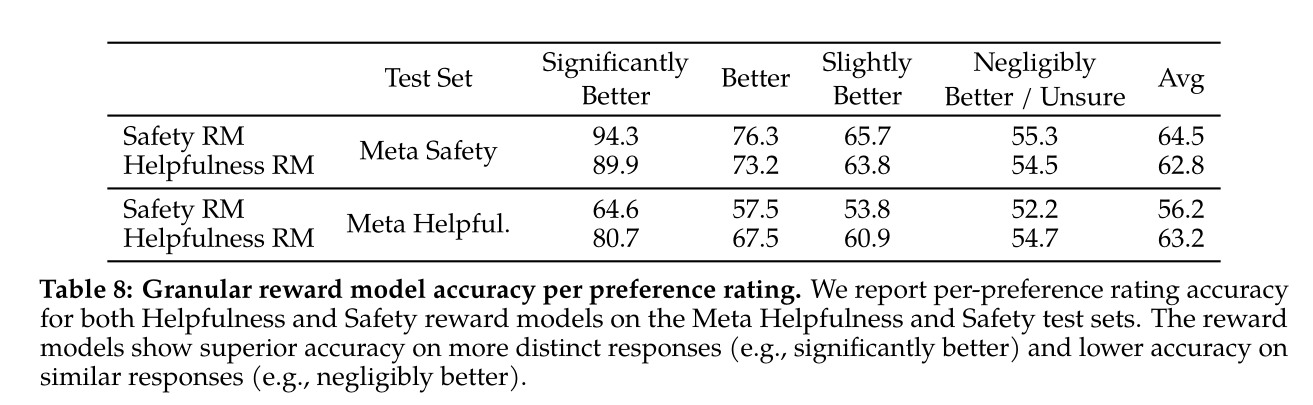
- “For GPT-4, we prompt with a zero-shot question “Choose the best answer between A and B,” where A and B are the two responses for comparison.”
- Fine tuning:
- PPO (Proximal Policy Optimization)
- Rejection Sampling Fine Tuning
- Burada genel RL ile alakalı fine-tuning processleri anlatılmış ama çok anlayamadımask
- GAtt (Ghost Attention)
- Bir prompt verdiğimde bunu tüm konuşma boyunca uygulmaasını istiyorum ama bir iki mesajdan sonra unutuyor → solution: GAtt
- Çeşitli promptları o ana kadarki tüm input output pairlarinin başına koyarak augmente ediyor ve SFT yapıyor